分布式文件系统HDFS特性
● 高度容错
整个HDFS系统将由数百或数千个存储着文件数据片断的服务器组成。实际上它里面有非常巨大的组成部分,每一个组成部分都很可能出现故障,这就意味着HDFS里的总是有一些部件是失效的,因此,故障的检测和自动快速恢复是HDFS一个很核心的设计目标。
● 高吞吐量访问
HDFS的每个数据块分布在不同的组服务器之上,在用户访问时,HDFS将会计算使用网络最近的和访问量最小的服务器给用户提供访问。由于数据块的每个复制拷贝都能提供给用户访问,而不是仅从数据源读取,HDFS 对于单数据块的访问性能将是传统存储方案的数倍。
● 支持大数据集
典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。
分布式文件系统 HDFS简介
随着信息系统的快速发展,海量的信息需要可靠存储的同时,还能被大量的使用者快速地访问。传统的存储方案从构架上已经越来越难以适应近几年来信息系统业务的飞速发展,成为了业务发展的瓶颈和障碍。
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。HDFS具有高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。
HDFS 通过一个高效的分布式算法,将数据的访问和存储分布在大量服务器之中,在可靠地多备份存储的同时还能将访问分布在集群中的各个服务器之上,是传统存储构架的一个颠覆性的发展。
分布式数据库HBase的特点
● 高可扩展性
HBase是真正意义上的线性水平扩展。数据量累计到一定程度(可配置),HBase系统会自动对数据进行水平切分,并分配不同的服务器来管理这些数据,这些数据可以被扩散到上千个普通服务器上。这样一方面可以由大量普通服务器组成大规模集群,来存放海量数据(从几个 TB 到几十 PB的数据)。另一方面,当数据峰值接近系统设计容量时,可以简单的通过增加服务器的方式来扩大容量。这个动态扩容过程无需停机,HBase系统可以照常运行并提供读写服务,完全实现动态无缝无宕机扩容。
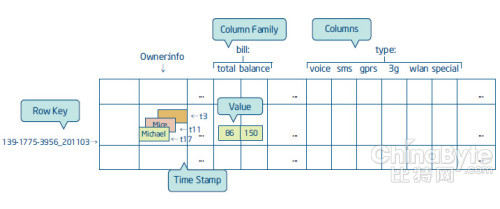
数据模型及其特点
HBase是一个面向列的、稀疏的、分布式的、持久化存储的多维排序映射表(Map)。表的索引是行关键字、列族名(Column Family)、列关键字以及时间戳,表中的每个值都是一个未经解析的字节数组。
分布式数据库 HBase简介
随着信息系统的快速发展,海量的信息需要可靠存储的同时,还能被大量的使用者快速地访问。传统的存储方案已经从构架上越来越难以适应近几年来的信息系统业务的飞速发展,成为了业务发展的瓶颈和障碍。
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。
HDFS 通过一个高效的分布式算法,将数据的访问和存储分布在大量服务器之中,在可靠地多备份存储的同时还能将访问分布在集群中的各个服务器之上,是传统存储构架的一个颠覆性的发展。
● 高性能
HBase的设计目的之一是支持高并发用户数的高速读写访问。这是通过两方面来实现的:首先数据行被水平切分并分布到多台服务器上,在大量用户访问时,访问请求也被分散到了不同的服务器上,虽然每个服务器的服务能力有限,但是数千台服务器汇总后可以提供极高性能的访问能力;其次,HBase设计了高效的缓存机制,有效提高了访问的命中率,提高了访问性能。
● 高可用性
HBase建立在HDFS之上,HDFS 提供了数据自动复制和容错的功能。HBase 的日志和数据都存放在 HDFS 上,即使在读写过程中当前服务器出现故障(硬盘、内存、网络等),日志也不会丢失,数据都可以从日志中自动恢复。HBase系统会自动分配其他服务器接管并恢复这些数据。因此一旦成功写入数据,这些数据就保证被持久化并被冗余复制,使得整个系统的高可用性得到保证。
