
从商业模式来说,人工智能的相关企业有三种:第一种是提供人工智能技术的公司,比如机器视觉、NLP等等;第二种是将人工智能与具体行业应用结合的公司,比如fintech、人工智能医疗、无人驾驶等等。而还有一种最容易被遗忘:为人工智能行业服务的公司。
飞速发展的人工智能产业,很容易让人看到技术售卖和行业迭代中的商业潜力。无论是巨头还是新晋独角兽,显然都在尽力提速,生怕掉队。但如此高的产业发展速度,事实上也催生了大量新的需求。这就像汽车的发展虽然盘活了交通运输,同时也催生了修车业的海量工作机会。
对于人工智能来说,这一类的机会有很多,比如说:数据清洗。
熟悉大数据的朋友应该对数据清理不会陌生,而在以机器学习为主要手段的AI爆发中,数据清洗也有了更重要的价值和愈发丰富的刚性需求。
很多AI创业者,可能忽略了这一环节带来的成本负荷和产能影响。
什么是数据清洗
按照惯例,咱们还是先来简单介绍一下什么是数据清洗。
数据清洗(Data cleaning)是大数据生产过程中的必须环节。我们知道,大数据发生效用来自于数据仓库对大数据的吞吐。但假如输入了错误或者无效的数据,那么输出时就会影响效果、产生误差,甚至造成bug。这些无效和错误的数据,被称为“脏数据”。而数据清洗顾名思义,就是要用各种手段把脏数据标记并清理出来。

数据清洗包涵多种目标和手段,比如检查数据一致性、处理无效值、识别数据冲突等等。并且整个过程包括多重审查、校验与标注。
我们采访过的很多大数据机构和云服务公司负责人都证实了这样的说法:数据清洗是成本消耗最严重的工作之一。
这项原本就非常吃重的工作,在人工智能潮中地位也跟着水涨船高了
举个栗子:AI中的数据清洗为何重要
在今天的主流AI工程化进程里,机器学习是最广泛使用的技术。而目前机器学习的主要实现手段是监督学习。
所谓监督学习,是由研发者使用已知数据集,让智能体基于标记的输入和输出数据进行推理,从而学习到达成目标的路径,让自己不断“聪明起来”。
理论上来说,智能体学习的数据越多就会越聪明,从而再生产出优质数据进行再学习,这样就可以不断完成自我进化。但这种最优状况,是建立在机器学习的数据都没错的情况下,假如其中混杂了错误数据,那么学习得出的结果显然也是错的。
更重要的是,机器学习想要达成,必须建立在数据的一致性和体系化基础上,假如错误数据造成了整个数据链的割裂,那么机器学习过程也将终止,就无从谈什么人工智能了。
举一个我们熟悉的例子:我们最常用的手机电商中,其实安插了大量机器学习算法来进行个性推荐。因为手机的屏幕显示量很小,假如推送的电商信息大多不符合用户期待,用户需要一直向下寻找,那么体验会很差,也影响电商体系的效率。这里就需要机器学习来建立用户个性化推荐模型,提供多种行为下的商品排序特征。
这个场景中的机器学习,必须建立在优质大数据的基础上,既要学习目标用户的数据样本,也要综合群体性数据和标签化数据,进行综合任务学习。而电商平台获取的数据,包括用户群的点击、搜索、购物车添加和收藏,以及最终的购买频次等等。但这些数据中可能掺杂大量的“脏数据”。

比如说用户点击后马上退出来,可能说明是错误点击行为;比如说用户搜索的关键词中含有错别字或者不可知内容;比如说用户购买后却普遍差评的商品,这些数据被机器学习后成为逻辑依据,转而推荐给用户,显然是不合适的。
这里就需要把电商数据系统中的缺漏数据、重复数据、错误数据剔除出去,保证机器学习内容的标准化和特征一致化。这之后剩下的优质数据才能提供给模型进行训练。
由此可见,数据清洗在人工智能的落地实现中是非常重要的一环。训练用的数据越多、训练模型越复杂,对数据清洗的工作需求量就越大。
假如人工智能飞速发展,数据清洗作为配图服务工种却没有跟上发展速度,那后果是很可怕的——想想《机器人总动员》里的小机器人,独自在垃圾星球中孤独而无尽的清理着。可以说是很可怜了……
数据清洗中也是亟待AI拯救的行业
这里说个题外话。如上所述,数据清理是个人工需求繁重、成本极高的工作种类,而且主要是和数据打交道。换句话说,这个工作具备进行人工智能升级的各种要素。
事实上,AI+数据清洗已经被广泛关注和讨论。目前最主要的结合方式有几种:
第一种是用机器学习技术训练智能体学习数据清洗的逻辑,从而优化数据清洗中的人工与机器工作分配比重。让一些人工分类、筛选和标注工作能够被机器执行,甚至准确率更高。
第二种是结合贝叶斯分类算法。贝叶斯分类是一种利用概率统计知识进行分类的算法,特征是分类准确率高、速度快,适合快速部署在数据归纳与统计当中。利用贝叶斯相关算法和技术,进行良性数据和脏数据的区分也在成为数据清洗的重要手段之一。
此外,其他利用文本识别算法与识别技术的AI能力来进行数据清洗的尝试也在逐渐增多。比如决策树、随机森林的算法都有根据特征判断不良数据的能力。算法识别主要可以增强特定领域的数据分析能力,更快投入实际应用。
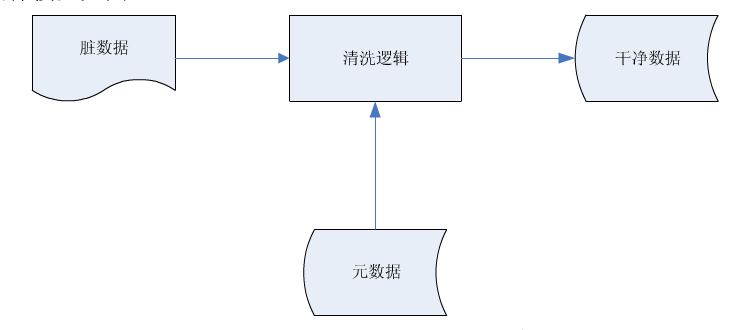
(数据清洗的基本流程,其中AI主要作用于清洗逻辑环节)
由此可见,数据清洗和人工智能是互相需要,无法分割的两类技术。以AI驱动数据清洗效率,反过来为AI体系服务,应该是未来的良性增长周期。
但从现阶段的情形看,二者结合任重道远。
缺口严重:AI配套服务产业的普遍现状
不仅是数据清洗行业,广泛来看,多种服务于AI硬件、数据和应用体系的配套产业发展都还远远不能达标。这点也是美国整个AI产业结构优于中国的重要环节,当然,即便是在美国,AI产业的发展与配套服务产业的建设速度也是不协调的。
目前来看这可能还不会形成巨大问题,但如果AI创业开始全面提速,个性化需求开始激增,那么配套设施的落后很可能成为行业的制约。
以针对AI产业的数据清洗为例,目前这个行业主要是面对大公司和集团企业服务,依旧保持着重度人工投入的劳动密集型特征。如果需求开始碎片化,服务成本很可能快速提升,成为创业者的成本负担。
其次,AI数据清洗服务相对集中的产业逻辑,也让适应创业企业的服务方案变成了稀缺品。一家以垂直领域AI为创业目标的公司,很难找到适合的数据清洗服务。从而不得不独立搭设数据服务部门,消耗大量精力和人力,也提升了“重新发明轮子”的创业门槛。
另外,传统云计算服务的数据清洗逻辑和人工智能的结合程度不够高,也限制了新的算法、模型投入使用时数据服务的跟踪服务能力。让很多技术创意较强或者海外引进的技术,在实践中无法部署。
数据层面的AI配套服务,主要集中在巨头手中,对创业群体而言障碍极多。当然这也可能是个新的创业机遇。把巨头独占的AI能力开放和定制化,很可能是AI企业服务中最大的机会之一。
AI是一座金字塔型的商业建筑。当然我们喜欢看塔尖上的珠宝,但最下一层没有人添砖加瓦的话,一切不过永远流于空谈而已。

 联系我们请点击:
联系我们请点击:



