每当提到机器学习,大家总是被其中的各种各样的算法和方法搞晕,觉得无从下手。确实,机器学习的各种套路确实不少,但是如果掌握了正确的路径和方法,其实还是有迹可循的,这里我推荐SAS的Li Hui的这篇博客,讲述了如何选择机器学习的各种方法。
另外,Scikit-learn 也提供了一幅清晰的路线图给大家选择:
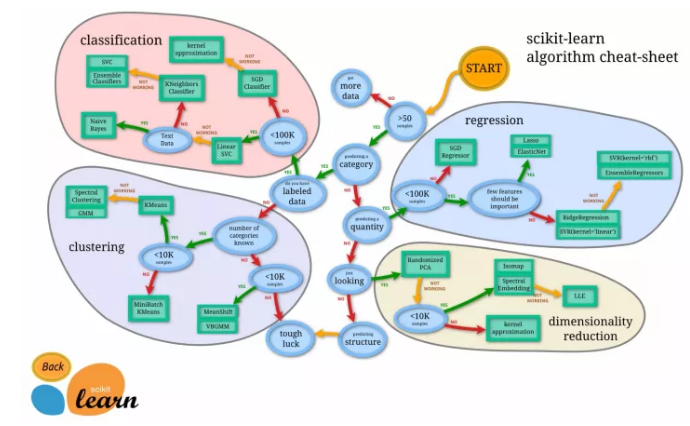
其实机器学习的基本算法都很简单,下面我们就利用二维数据和交互图形来看看机器学习中的一些基本算法以及它们的原理。(另外向Bret Victor致敬,他的 Inventing on principle 深深的影响了我)
所有的代码即演示可以在我的Codepen的这个Collection中找到。
首先,机器学习最大的分支的监督学习和无监督学习,简单说数据已经打好标签的是监督学习,而数据没有标签的是无监督学习。从大的分类上看,降维和聚类被划在无监督学习,回归和分类属于监督学习。
无监督学习
如果你的数据都没有标签,你可以选择花钱请人来标注你的数据,或者使用无监督学习的方法
首先你可以考虑是否要对数据进行降维。
降维
降维顾名思义就是把高维度的数据变成为低维度。常见的降维方法有PCA, LDA, SVD等。
主成分分析PCA
降维里最经典的方法是主成分分析PCA,也就是找到数据的主要组成成分,抛弃掉不重要的成分。
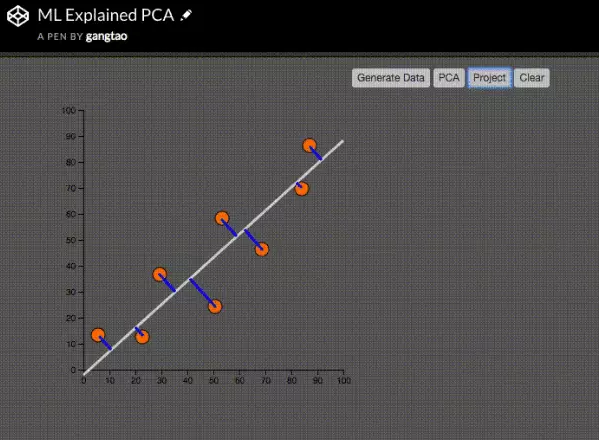
这里我们先用鼠标随机生成8个数据点,然后绘制出表示主成分的白色直线。这根线就是二维数据降维后的主成分,蓝色的直线是数据点在新的主成分维度上的投影线,也就是垂线。主成分分析的数学意义可以看成是找到这根白色直线,使得投影的蓝色线段的长度的和为最小值。
聚类
因为在非监督学习的环境下,数据没有标签,那么能对数据所做的最好的分析除了降维,就是把具有相同特质的数据归并在一起,也就是聚类。
层级聚类 Hierachical Cluster
该聚类方法用于构建一个拥有层次结构的聚类

如上图所示,层级聚类的算法非常的简单:
1、初始时刻,所有点都自己是一个聚类
2、找到距离最近的两个聚类(刚开始也就是两个点),形成一个聚类
3、两个聚类的距离指的是聚类中最近的两个点之间的距离
4、重复第二步,直到所有的点都被聚集到聚类中。
KMeans
KMeans中文翻译K均值算法,是最常见的聚类算法。
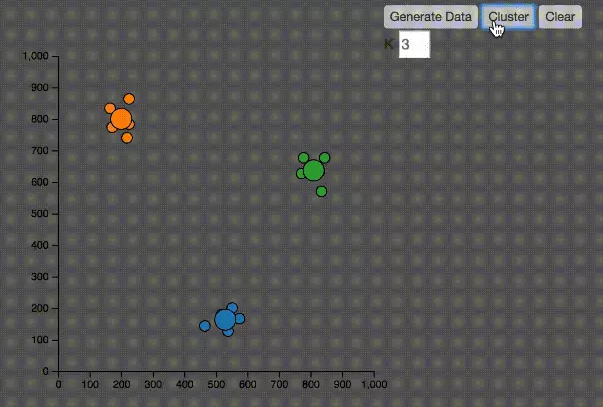
1、随机在图中取K(这里K=3)个中心种子点。
2、然后对图中的所有点求到这K个中心种子点的距离,假如点P离中心点S最近,那么P属于S点的聚类。
3、接下来,我们要移动中心点到属于他的“聚类”的中心。
4、然后重复第2)和第3)步,直到,中心点没有移动,那么算法收敛,找到所有的聚类。
KMeans算法有几个问题:
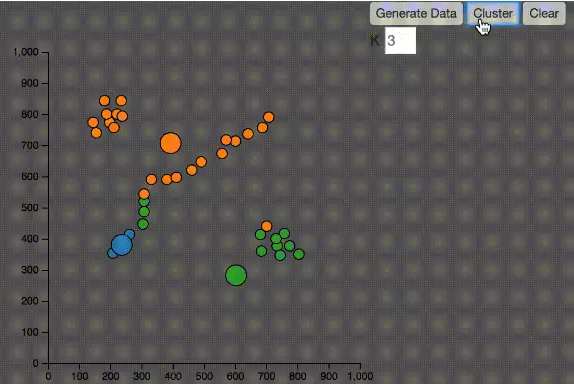
1、如何决定K值,在上图的例子中,我知道要分三个聚类,所以选择K等于3,然而在实际的应用中,往往并不知道应该分成几个类
2、由于中心点的初始位置是随机的,有可能并不能正确分类,大家可以在我的Codepen中尝试不同的数据
3、如下图,如果数据的分布在空间上有特殊性,KMeans算法并不能有效的分类。中间的点被分别归到了橙色和蓝色,其实都应该是蓝色。
DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)中文是基于密度的聚类算法。
DBSCAN算法基于一个事实:一个聚类可以由其中的任何核心对象唯一确定。
算法的具体聚类过程如下:
1、扫描整个数据集,找到任意一个核心点,对该核心点进行扩充。扩充的方法是寻找从该核心点出发的所有密度相连的数据点(注意是密度相连)。
2、遍历该核心点的邻域内的所有核心点(因为边界点是无法扩充的),寻找与这些数据点密度相连的点,直到没有可以扩充的数据点为止。最后聚类成的簇的边界节点都是非核心数据点。
3、之后就是重新扫描数据集(不包括之前寻找到的簇中的任何数据点),寻找没有被聚类的核心点,再重复上面的步骤,对该核心点进行扩充直到数据集中没有新的核心点为止。数据集中没有包含在任何簇中的数据点就构成异常点。
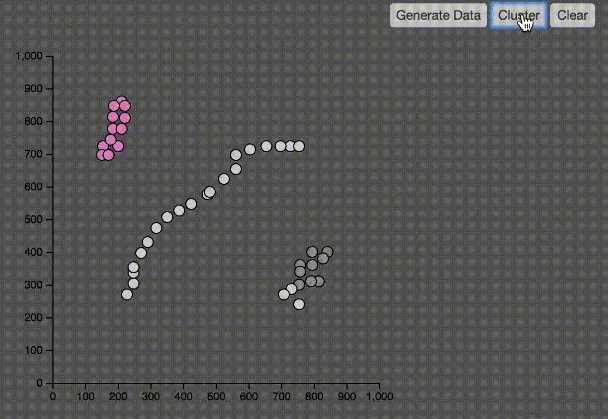
如上图所示,DBSCAN可以有效的解决KMeans不能正确分类的数据集。并且不需要知道K值。
当然,DBCSAN还是要决定两个参数,如何决定这两个参数是分类效果的关键因素:
1、一个参数是半径(Eps),表示以给定点P为中心的圆形邻域的范围;
2、另一个参数是以点P为中心的邻域内最少点的数量(MinPts)。如果满足:以点P为中心、半径为Eps的邻域内的点的个数不少于MinPts,则称点P为核心点。
监督学习
监督学习中的数据要求具有标签。也就是说针对已有的结果去预测新出现的数据。如果要预测的内容是数值类型,我们称作回归,如果要预测的内容是类别或者是离散的,我们称作分类。
其实回归和分类本质上是类似的,所以很多的算法既可以用作分类,也可以用作回归。
回归
线性回归
线性回归是最经典的回归算法。
在统计学中,线性回归(Linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。
这种函数是一个或多个称为回归系数的模型参数的线性组合。 只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。

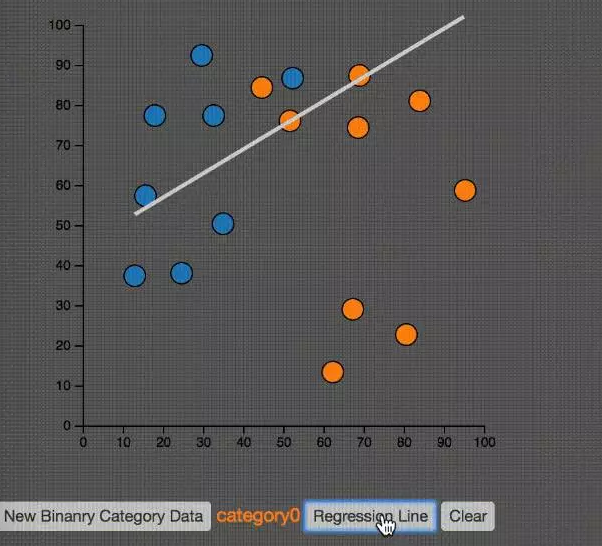
如上图所示,线性回归就是要找到一条直线,使得所有的点预测的失误最小。也就是图中的蓝色直线段的和最小。这个图很像我们第一个例子中的PCA。仔细观察,分辨它们的区别。
如果对于算法的的准确性要求比较高,推荐的回归算法包括:随机森林,神经网络或者Gradient Boosting Tree。
如果要求速度优先,建议考虑决策树和线性回归。
分类
支持向量机 SVM
如果对于分类的准确性要求比较高,可使用的算法包括Kernel SVM,随机森林,神经网络以及Gradient Boosting Tree。
给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。
SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。

如上图所示,SVM算法就是在空间中找到一条直线,能够最好的分割两组数据。使得这两组数据到直线的距离的绝对值的和尽可能的大。
上图示意了不同的核方法的不同分类效果。
决策树
如果要求分类结果是可以解释的,可以考虑决策树或者逻辑回归。
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树可以用于回归或者分类,下图是一个分类的例子。
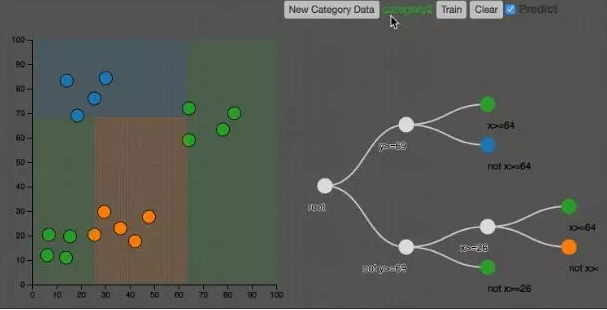
如上图所示,决策树把空间分割成不同的区域。
逻辑回归
逻辑回归虽然名字是回归,但是却是个分类算法。因为它和SVM类似是一个二分类,数学模型是预测1或者0的概率。所以我说回归和分类其实本质上是一致的。
这里要注意逻辑回归和线性SVM分类的区别

朴素贝叶斯
当数据量相当大的时候,朴素贝叶斯方法是一个很好的选择。
15年我在公司给小伙伴们分享过bayers方法,可惜speaker deck被墙了,如果有兴趣可以自行想办法。

如上图所示,大家可以思考一下左下的绿点对整体分类结果的影响。
KNN
KNN分类可能是所有机器学习算法里最简单的一个了。
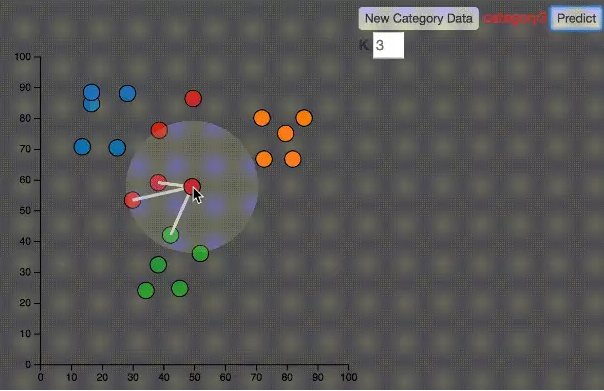
如上图所示,K=3,鼠标移动到任何一个点,就找到距离该点最近的K个点,然后,这K个点投票,多数表决获胜。就是这么简单。
总结
本文利用二维交互图帮助大家理解机器学习的基本算法,希望能增加大家对机器学习的各种方法有所了解。所有的代码可以在参考中找到。欢迎大家来和我交流。
参考:
代码和演示动画
我的Codepen Collection 包含了所有的演示代码
我的github包含了所有的演示动画
基于JavaScript的机器学习的类库和演示
Machine learning tools in JavaScript 基于JavaScript的机器学习库,本文中的一些演示用到了该库。
另一个基于JavaScript的机器学习库,没有前一个功能多,也没有前一个活跃,但是有很好的演示
不错的演示,有三种回归和一个聚类
如果你像想要自己构建机器学的算法,可以用到的一些数学基础类库
Numeric Javascript 是基于JavaScript的数值计算和分析的类库,提供线性代数,复数计算等功能。
Mathjs 另一个基于JavaScript的数学计算库,这个和前一个可以看作是和Python的numpy/scipy/sympy 对应JavaScript的库。
Victorjs 2D向量库
推荐一些机器学习的路线图
https://ml-cheatsheet.readthedocs.io/en/latest/
10大机器学习算法 https://www.gitbook.com/book/wizardforcel/dm-algo-top10
http://blogs。sas。com/content/subconsciousmusings/2017/04/12/machine-learning-algorithm-use/
http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
工具
把mov文件在线转换为动图 https://convertio.co/zh/mov-gif/ 或者 https://cloudconvert.com/mov-to-gif
gif 编辑工具 https://ezgif.com
 联系我们请点击:
联系我们请点击:



