导语:古有水泊梁山英雄108将叱咤江湖,今有"中国大数据技术先锋108将"高端人物访谈搅动风云。2017年,由DT学院、中国城市报大数据中心、清华大数据产业联合会、山西省大数据产业协会联合举办,面向大数据产业的技术精英、专家学者以及大数据产业链领域公司CTO的"中国大数据技术先锋108将"高端人物访谈活动正式启动,围绕大数据技术的多个层面进行分享,旨在搭建大数据技术传播分享的高端平台,促进大数据技术的业内交流。
第2期专访人物

中国顶尖数据科学家 卢亿雷
卢亿雷:大数据资深专家,精硕科技(AdMaster)技术副总裁兼总架构师,CCF(中国计算学会)大数据专委委员,北京航空航天大学特聘教授,新智元智库专家。关注数据采集、清洗、存储、挖掘整个数据流过程,关注高可靠、高可用、高扩展、高性能系统服务、Hadoop/HBase/Storm/Spark/ElasticSearch/Druid等离线、流式及实时分布式计算服务。有超过10年云计算、云存储、大数据经验。曾在联想、百度、Carbonite工作,并拥有多篇大数据相关的专利和论文。
访谈主题
社交数据情感分析的大数据应用实践
访谈录
DT学院:作为业内资深人士,能先给大家介绍一下自己的技术经历吗?
卢亿雷:2006年硕士毕业后就加入联想研究院,印象最深的就是跟我们一位同事一块折腾过约50万行 C++代码),使自己的代码能力得到显著提高。
后来加入百度系统部核心 Hadoop 组,之后又合并到基础架部,使我对 Hadoop 有了更深的理解与体会。 另外就是离开百度加入 Carbonite China 是一次创业的选择,当时在 中国的时候连 Office 都没有就开始一起做事了,这使我熟悉了整个创业过程, 使自己在技术、产品、管理方面都有了非常大的提升;2013年加入AdMaster,我作为技术副总裁兼总架构师,负责公司的完整数据流过程服务(包括采集,清理,存储,挖掘等)。Hadoop/HBase/Storm/Spark/ElasticSearch/Druid等离线、流式及实时分布式计算服务等多方面均有深入研究与应用。
DT学院:作为业内人士,您对大数据是如何理解的?
卢亿雷:大数据不仅仅是指海量的数据,而是指和大数据相关的整个流程。数据流之所以称之为数据流,是因为只有当数据流动起来,才能发挥其真正的意义。如果只是海量的数据摆在那里,无异于一潭死水,毫无生机。整个流程中的每一个环节,无论是最初的采集,之后的清理,存储,后期的分析,都至关重要,并且每一部分都有其相对应的技术来进行处理。大数据目前进入一个平稳期,其更偏向于实际的应用如人工智能、深度学习、区块链等。大数据最终目的必定是为人类带来多方面收益和便利。
DT学院:根据您的观察和研究,在大数据领域有哪些关键性技术?经历了怎样的发展历程?
卢亿雷:大数据存储技术,HDFS,HBase,ElasticSearch,MongoDB,GlusterFS,FastDFS,Swift等这些技术已经成为开源界事实上的标准,从刚出现时的种种稳定性BUG,到现在坚不可催,并且出现了越来越多的新功能。
大数据计算,从最开始的MapReduce一统江湖,到后来 Yarn、Storm、Tez,再到现在 Spark、Flink、Apex 等更高效更易用的计划框架百花齐放,可做的选择越来越多,并且可以在大数据基础上做机器学习、人工智能等多种应用。
多维实时分布式查询,随着 Druid、Kylin、vertica 等开源和商用OLAP 系统的成长,大数据层面的秒级查询,也渐渐走近我们。Alluxio 这一存储中间层的出现,让计算向着更快更廉价的方向又给出了一个新的方案。
大数据技术有一个发展趋势,就是功能越来越强大,使用门槛越来越低,所以开始走向大众企业。
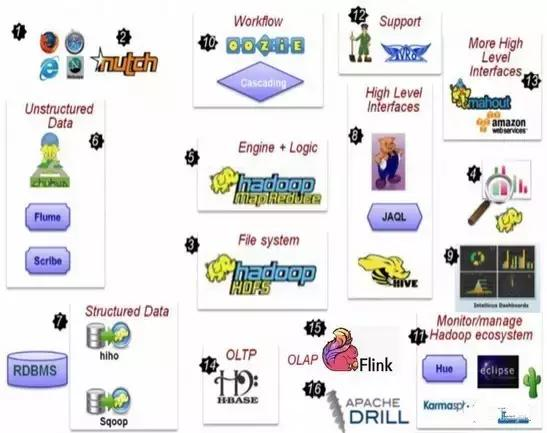
大数据技术发展路线图
DT学院:您所在的公司,使用过哪些大数据技术?你对这些技术满意的地方和不满意的地方分别有什么?
卢亿雷:现在流行的大数据技术, AdMaster 基本上都在使用或使用过。
HDFS + MapReduce + HBase 的标准 3架马车,伴随着我们的一些业务一直运行到现在,但是对于一些实时性要求较高的业务开始显示出它们的不足。
Spark、Flink 在对"快"有着最高要求的业务里,扮演着重要角色,广告业务的实时监控,基础报告的 Lambda 架构, 都是由这两个框架来支持,这两种技术在 Yarn 上的稳定性,还有进一步提高的空间。
Vertica 和 ElasticSearch 则在对于多维数据分析和 OLAP 的业务上发光发热,比如广告业务的多维数据呈现,社交数据的实时处理。这两个技术, 在超大规模数据集场景下,还有待进一步提高。
DT学院:可否结合具体应用场景,给我们分享一个案例?
卢亿雷:这里可以给大家分享一下 AdMaster 用于支持精准营销的 DMP 标签平台。大家知道,要做到精准营销,关键点在于发现这个人对什么感兴趣,即对于每个人给出他感兴趣的标签。
这涉及到几个小问题,网民在查找手机相关的内容,他应该是对于手机感兴趣,那怎么在他下一个访问的页面,就给他看到手机的广告?也就是从发现数据到数据生效,要快。为了解决这个问题,AdMaster 使用了改进版的 Flume 来进行实时传输数据,接入 Kafka,使用 Spark 和 Flink实时处理数据入库,从一个数据的产生到入库,时间可以控制在 10 秒以内。
10 秒可能大家觉得已经太久了, 但是我们每天处理的数据量在 100 亿以上,还要累积最近 45 天内的所有数据,为了达到快的要求, AdMaster 使用了 AeroSpike 集群做为数据存储, 可以达到400万的 QPS。
为了分析出每个页面代表的内容,AdMaster 研究院独立研发了自己的内容分析系统,以保证准确分析出页面内容。AdMaster 与新浪微博达成了战略合作关系,保证数据的及时性和稳定性。
DT学院:您对社交数据情感分析颇有研究,请您给大家讲下社交数据情感分析及应用现状?
卢亿雷:社交数据情感分析是商业用户的一个诉求,各大商业公司在做广告的同时,还会在自己的微博和微信等社交平台上发布一些信息,就是所谓的官方微信、官方微博。同时,也会有人在这些账号上作评论,或者是在个人的社交账号上发一些言论。企业用户比较关心的是"是不是有人说我坏话了?" 、"是不是竞争对手又搞什么动作了?" 。 前一个问题, 就是现在社交数据情感分析的一个主要诉求。简单说就是,企业用户想尽快知道是不是有人说他坏话了。
社交数据情感分析应用有:用户画像与精准营销、产品比较与推荐、个人与机构声誉分析、电视节目满意度分析、用户反馈分析、互联网舆情分析危机公关、未来的预测、KOL分析等。
目前社交数据情感分析已经不是简单的情感分析了,在朝着人工智能、深度学习、智能客服等方向发展了。
DT学院:社交数据情感分析用到哪些技术和工具?目前的技术瓶颈是什么?期待有什么改进?
卢亿雷:用到的技术有:网络爬虫,分词,语义分析,句法分类,相关性判断,分类模型等。
难点:
情感本身很主观,同一句话,写作者和阅读者对于情感的判断可能是相反的,有语义歧义。
客户一般要求速度要快,行业内有基于规则匹配的方法,对短句(20 个词以内)有效, 但是长句一般都会标错。
语料中有关于两个关键词比较的,不好判别情感;基本上是一个在某方面好,另一个在另一方面好。
客户一般要求模糊查找,近义词同义词或相关词语查找,但是真正使用时往往用的又不是事先约定的关键词,所以不能提前标注。又要求速度快,挑战比较大。
DT学院:国际上有哪些技术创新和新型的开发工具?与国际大数据技术对比,我国大数据技术处于怎样的发展水平?
卢亿雷:Apex 可以算是目前国际上大数据领域创新方向的一个代表,计算原子化,易组合,数据尽可能内存计算,同时支持批处理和流式计算,可以对接多种大数据生态。
近几年随着互联网开源运动的发展,国内的大数据技术已经在渐渐融入国际社会,百度、阿里、华为等互联网企业已经开始在开源界展露头角,在2015年Spark Summit大会上,Spark最大的集群来自于腾讯有8000个节点,单个Job最大分别是阿里巴巴和Databricks为1PB,非常震撼人心。比如阿里对 Storm 贡献的 Jstorm,百度对 Hadoop 贡献的 HCE,华为对大数据存储贡献的CarbonData 等等,可以说,我国的大数据技术,已经完全融入国际环境,有世界上最多的网民支持,已经开始在某些领域引领大数据的发展方向(比如双 11 造就的"瞬间大流量处理")。
最后,我们可以非常自豪的说中国的大数据技术已经走在世界前列了。
DT学院:根据您的判断,大数据技术未来会有怎样的发展?又会面临怎样的挑战和机遇?
卢亿雷:毫无疑问的是,大数据技术有着光明且长远的未来。尽管大数据相关的技术已经发展了十余年的时间,但是我们面对的仍是渺无边际的技术蓝海。
举一个例子,在过去的十年中,我们可获取的数据量在飞速的提升。我们不再满足获取局限于互联网上已有的数据,而随着物联网技术的进步,我们生活中的每一个事物都先后被安上传感器,接入互联网,纳入了大数据的范畴。面对激增的数据量,我们应该如何应对?在增加硬件设施的同时,是否也在技术算法上做出了相应改进?面对种类更加繁杂的数据,现有的分析模型是否已经不能满足需求?挑战千变万化,我们需要打好技术基础,方能解决这些难题。
随着大数据技术的发展,使得企业日生产量在逐渐增加,尽管近60%的企业日生产量不到1T,但是由于此处统计的是裸数据增长,所以企业实际占的存储可能会大于3T(大数据企业一般会将数据存储3份);有部分的企业选择"自主研发",这里主要是包括了基于大数据平台开发应用、二次开发等,而不是企业自己开发一个类似于Hadoop这样的大数据系统;HDFS依然是企业构建大数据分布式存储的首选架构;在分布式计算领域,MapReduce仍然是最通用的计算框架,Spark也是来势凶猛,不过实际生产线上MapReduce的占比可能还要更高一些,但是随着实时计算的快速发展,像类似于Spark、Flink都会快速成长;由于ElasticSearch的迅速发展,使得日志数据可视化工具ELK(ElasticSearch+Logstash+Kibana)得到较高的使用,而像用于大数据实时查询和分析的分布式系统如Druid、Pinot等发展也越来越快;最后企业对于大数据人才的需求越来越多,要求也越来越高,不光是技术要好,业务也需要了解。
DT学院:对于大数据技术学习者,如何更高效的掌握大数据技术,您有哪些建议?
卢亿雷:对于大数据技术学习者,最基本一定要掌握大数据技术处理的流程,包括有数据采集、清洗、存储、分析与挖掘、数据可视化,理解大数据分为离线、在线、流式、实时系统;了解大数据OLTP与OLAP分布式多维实时查询系统的区别等。总之,不管大数据技术如何发展,对分布式系统理论一定要有深入理解,万变不离其宗。最后实践是检验真理的唯一标准,多动手实践,多与业务结合一起实践,有条件的去类似于大数据汽车、快消品、金融、地产、广告等公司实践。
DT学院:对于大数据教育培训的课程类型设计、教学设计,您有哪些看法和建议?
卢亿雷:根据面向的听众不同,可以分成两个大类:
入门级听众,对大数据仅仅是听说过,或做过一些类似 helloworld 之类的小实验, 可以系统地安排讲解大数据发展史,知其然知其所以然,并尽可能全面地介绍大数据的发展方向,最关键的是各方向形成的原因,应用的场景,可以解决哪些问题,简要介绍一些案例。
高级听众,使用过或正在使用大数据技术,更关心的应该是应用场景,以及使用中各种总是的解决方案。对于这类听众,应更多地结合实际案例,讲解各种常见故障及解决方案,切实解决工作中的问题。
媒体支持
人民网、新华网、中国城市网、央视网、中国城市报、经济日报、中国新闻网、封面传媒、中国日报网、央广网、每日经济新闻、腾讯科技、新浪科技、搜狐科技、网易科技、中国大数据产业观察网、大数据科技视界、DT学院、199IT、数邦客、DT私享汇、 数据猿、中国大数据、大数据人、大数据文摘、大数据周刊、数据分析师、09大数据、研趣网、大数据中国、咕噜网、 界面新闻、 中国科技信息杂志社、今日头条
 联系我们请点击:
联系我们请点击:









