11月23-24日,"2017互联网+智慧中国年会"在北京万寿宾馆召开。本届年会以"智绘城市 数造未来"为主题,以数字政府、智慧城市、互联网+政务服务、数据治理、信息社会等为主要议题。会议由中国社会科学院信息化研究中心、北京国脉互联信息顾问有限公司联合主办,国脉海洋信息发展有限公司、浙江蟠桃会信息技术有限公司协办,共有来自全国部委/省/市/区县电子政务、智慧城市、大数据主管领导、行业专家、企业代表、主流媒体千余人参会。
在23日下午的"2017政务信息系统整合共享与数据资产普查研讨会"上,拓尔思政企事业部副总经理刘新华以《共享改变模式·拓尔思案例分享》为主题进行了演讲。

▲拓尔思政企事业部副总经理刘新华
以下是会议现场发言实录:(根据速记和录音整理,未经本人审核)
今天给大家分享一下我们刚上线的一个项目,也比较干货的一些内容。
一.普查
我们这些项目也是以普查为基础,就是说在往下汇报的时候,我们先对普查有个概念。普查是大规模的对一个国家或者一个地区进行国情、国力的全面调查,搞清楚重要的国情国力,一般调查的是在一定时间内的社会现象的总量,但是也可以调查某一时间段社会的一个情况,普查涉及的面比较广、指标多、工作时间紧,所以说为了取得比较准确的统计资料,普查是集中领导的一个行动,有着很高的要求。
所以普查也是随着中国经济发展必然产生的社会活动,普查涉及到的方面比较多。常见的普查包括1953年的人口普查,2004年的经济普查,1997年的农业普查,2007的农业源普查,政府的网站普查、工业普查、第三产业普查等等。
普查的特性:
普查有5个特性,第一是广泛性,它涉及到的地区广,涉及到企业、工业和地质方向的信息。
第二个是时间性,时间范围不宜过长,我们今天分享的案例也是涉及到污染源普查的情况。
第三是科学性,我们对普查要求的指标项多、维度广,我们在准确和科学地进行普查填报之后,对后期的估算和统计有着至关重要的作用。
第四个是准确性,不同的人群、学历和专业、地域环境等等对于数据的采集是有差异化的。
第五是安全性,普查涉及到国家国力、国情的基本信息,针对数据上传、下达都需要有相关手段进行管理防止泄密。
二.第二次全国污染源普查基本单位名录数据预处理服务
1.项目背景
国办2017年正式发布"国办发〔2017〕82号"《国务院办公厅关于印发第二次全国污染源普查方案的通知》,制定了第二次全国污染源普查方案,明确了普查工作目标、普查时间、对象、范围和内容、普查技术路线、普查组织及实施、普查经费、普查质量管理;
第一次全国污染源普查方案明确了几个方案。第一是以报送为主,时间性、准确性比较差,填报的可性度比较低,数据需要二次录入,维度也比较少,不利于后期的应用,违背了我们对污染普查广泛性的一系列要求。
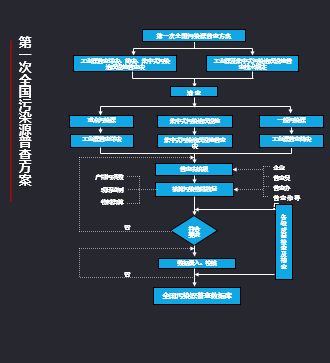
▲第一次全国污染源普查方案
2.数据处理新思路
总结第一次污染普查的问题,第二次污染普查使用到新思路、新手段,通过获取国家统计局、国家工商总局、国家税务总局和电网提供业务性数据,结合业务环保数据,开展了数据的清洗,按照第二次普查对象的要求,对数据进行对比、校验、审核,最后对数据进行标准化的处理,最终达成项目的目标。
3.项目实施难点
项目的思路有了,接下来对数据进行梳理,各部委地方提供了不同的时间段的数据,同时也遇到一些难点问题:
(1)数据格式不统一,表现为数据字段不统一、数据文件格式问题;
(2) 数据质量参差不齐,包括一些工商的数据没有组织机构代码,统一的数据代码;
(3)数据量也比较大,整个数据量加起来应该有七千到八千万的数据量;
(4)周期也比较短,我们是11月前期拿到的数据,要在两个月的时间进行数据交付。我们对数据的项目分析来看,时间紧、任务重,需要使用高效便捷的工具,通过企业资源的积累,整个项目过程才能起到事半功倍的作用。
4.2+2解决项目难点
这次我们分享的项目是使用了拓尔思的ETL工具、大数据存储、企业存量的服务性数据、地理位置服务数据两大资源,所以我们也对本次的项目提供"2+2"的一个解决方式。
(1)ETL工具。这是我们的ETL清洗工具,在项目过程中起到了很大的作用。同时也有一款自主研发的产品,有较大的数据集成能力,能够帮助客户修正数据质量,汇聚多数据源,转化数据形态,提升数据的利用价值,并且工具也利用OSGI插件的模式进行开发,所以对于后期的第三方数据接入,可以快速以插件的方式集成在应用里边,同时也提供了WEB的访问。

▲ETL工具
(2)大数据存储。数据储存也作为本次项目一个关键的软件产品,它决定了数据的处理效果,项目交付以后,后期对数据共享做重要的数据支撑,海贝(音)在项目中也发挥了很大的作用,它有着分布式和读写分离的特点,对于数据检索也起到了非常重要的作用。
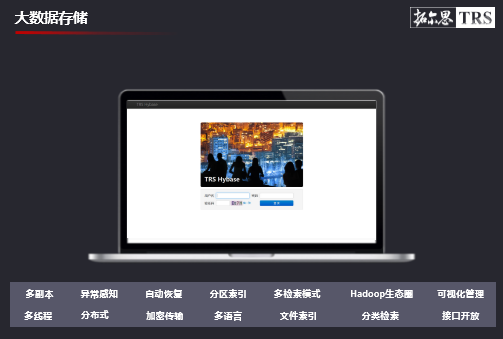
▲大数据存储
我们拓尔思拥有全行业企业的信息库,这个信息库主要是数据清洗的一个整库,我们知道现在去工商注册,注册完了以后,除非你去工商做企业变更,不然企业的相关信息,比如说企业是不是在存活,企业是不是皮包公司等,工商是不知道的。因此我们对企业的存量数据也在进行清洗,这也对我们的项目也起到了至关重要的作用。我们会利用这些数据处理,对基础性数据打标签,同时也满足了这些新项目的要求,因为数据要在完全的物理隔离下才能进行,我们进行了数据落地的方式,同时数据是在线服务,我们也有在线服务的一个提供。
(3)企业存量数据。也是本次项目需要完成的重要工作之一,最后的数据提供也要根据数据位置编码的方式,对相关的业务进行测算、补全。
(4)地理位置数据。地理位置的信息可以精确到企业的数量和分布,测算后的数据主要投入到下一步客户的工作部署,测算出一个人员的投入量情况,拓尔思的地理位置编码库也分布在企业的各个位置,提供在线和离线的数据包和接口式的服务。
(5)来源数据自清洗
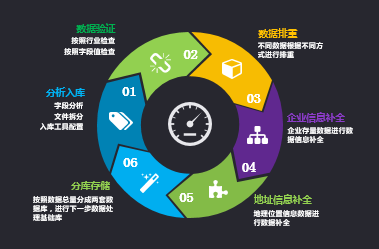
▲来源数据自清洗
数据基础的思路是进行数据处理,数据先进行自清洗,去除统一标准,对数据进行补充。每列的重复方式也不一样,比如工商的数据变更一次,然后数据就会有新增的一次。我们通过一些标签和其他的进行分析,把这些工商的数据、税务的数据,先进行排除。因为数据来源的标准都是不一样的,我们要制定统一的标准,每个企业跟每个人是一样的,每个企业都有唯一的标识,这种标识对提供方的数据也是不全的。对企业信息的标准来说,机构代码和地质码也有几个标准,有了标准以后,就为项目的开展提供了一个有利的保障。
(6)交叉对比。有了较为干净和统一标准基础库后,我们就可以进行数据交叉对比,以统计局为基础库,利用工商、质检、环保业务自清洗后的数据进行交叉对比和数据补充,最后再以税务、电力数据为企业活跃状态标识进行打签,完成整个名录库的构建。
(7)数据验证。在数据交叉对比完毕后,最后要做数据验证,数据验证也是从四个方面入手:
①是通过汇集的总数据与来源库数据进行对比,通过行业分类数量、地区数量等维度进行核对;
②是数据抽样和常识性校验,主要也是根据以往的经验,例如与第一次普查的结果进行对比,针对工业源的前5进行排序对比(浙江、广东、江苏、山东和河北省普查对象数量居前5位),再例如对于沿海地区的矿产企业进行检查,我们知道沿海地区的矿产企业很少,如果出现了异常就需要去检查流程;
③是第三方的应用系统对接 ,按照普查的部署,下一步我们要和清查进行对接,最终也要将数据上到正式的地图上,因此这也算是一项数据校验的工作;
④业务先行的验证,例如一些普查对象的前期摸底等。
通过本次分享的案例,我们也看到了政府对数据开放和各部门间的协调作用,数据只有不断流动才能发挥它更大的作用,数据整合和数据共享的时间和方法都比较明确,拓尔思也在积极整合政府跨时代的变革,也不断地优化技术创新,为国家的策略、战略做好服务和支撑。
今天就到这里,谢谢大家。
 联系我们请点击:
联系我们请点击:



