据报道,微软亚洲研究院有一位大名鼎鼎的个人助理EDI(音同Eddie),从帮助员工预订会议室到更新梳理公司内部“八卦”信息,随叫随到全年无休;不仅如此,EDI对员工们的喜好也堪称了如指掌。EDI是人工智能系统,它拥有精准的自然语言理解和对话能力;另一方面,利用深度学习和社交网络融合等前沿技术,EDI为每个用户构建了一张关于他们的职场知识图谱。

什么是职场知识图谱?
职场知识图谱也叫做EDI Graph(Enterprise Deep Intelligence Graph),图谱内的信息包括员工的部门、技能、项目、文档、时间、会议室和办公室等,其中每条信息又有各自丰富的属性,信息与信息之间也存在丰富的关联;这些信息的来源主要分为企业内部数据和互联网数据两部分,其中,企业内部数据主要包括内部网页、文档、会议记录、员工基本资料等数据,互联网数据则主要包括维基百科、学术论文、LinkedIn等公开数据。如何将来自公司内部、社交网络、Web等不同来源的异构数据进行梳理和融合、构成一张完整的职场知识图谱,这是构建EDI Graph的关键技术。

国内知名大数据专家、职品汇创始人龚才春博士认为,构建职场知识图谱最关键的是要有丰富的企业内部数据及互联网大数据的支撑,人工智能知道信息越多就越能了解人以及人与人之间的关系,越接近员工的工作知己。
人工智能如何把有效信息融合
国内知名大数据专家、职品汇创始人龚才春博士指出,对于相同的事,人与机器往往有着不同的理解与表达,人们在不同情境下可能选择多样化的表达方式,这些表达上的差异无法用简单的字符串匹配或缩写匹配的方式来完成相似度的计算。那么,人工智能该如何区分同一事物的不同指向呢?

一般的做法是将这些千变万化的表达看作不同的语言,通过机器翻译技术,找到词与词之间具有的某种翻译关系,从而实现相似词语的融合。
首先,利用种子规则,找到信息中高准确度的种子节点对,利用种子节点对中属性的不同表达,构建平行语料库。之后,使用深度学习技术构建翻译模型,完成不同信息源之间的属性“翻译”。通过机器翻译,不仅能计算简单字符串匹配无法计算的相似表达,甚至还能计算不同语言中同一表达的相似度,让机器人能够吸收消化更多更广泛的信息来源,对用户的表达做出更准确的判断。

得到不同表达的相似度之后,如何精准对应也是一门学问。例如,只要给个人助理EDI发送一条非常简洁的信息“帮我和David订个会议室”,人工智能系统就能帮助员工准确预订好会议室。然而只要打开微软员工目录,就会发现名为David的员工大约有两千名,人工智能系统如何分辨他们并从中确定要和用户开会那个David究竟是哪一个呢?要知道,这两千位名为David的员工,有些位于同一部门,甚至职务也都相同,这时,单单通过机器翻译得到的属性相似度,可能无法做出正确的对应。
精确匹配的突破口在于不同David的职场知识图谱,其网络结构也是不同的,使用协同训练(Co-Training)的方法,迭代地进行图结构信息的匹配。在每一轮迭代中,首先利用当前已匹配的实体对,更新神经网络翻译模型,并利用更新后的模型完成属性间的相似度计算;同时,根据当前已匹配节点计算待匹配节点的公共相邻节点对,通过结合属性匹配和图结构,可以得到新的匹配集合,如此迭代直到收敛。

简单说,人工智能系统能将职场知识图谱中同一个David的信息融合到一起,把不同的David放在各自节点上,然后通过参会历史、项目合作、内部的汇报关系等等,了解公司同事之间的远近,从而锁定用户真正想找的David,完成用户交给的安排会议并预订会议室的任务。
深入挖掘数据信息是构建职场知识图谱的关键
人工智能系统在掌握丰富的信息之后,也需要进一步分析和理解这些数据,才能深入了解企业中的每一个员工。
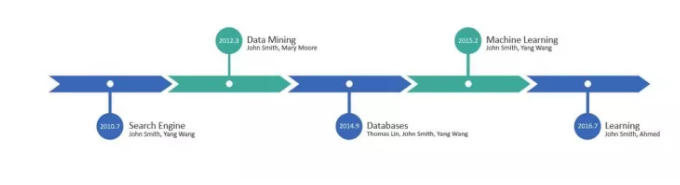
在一个企业中为员工构建职场知识图谱,最为基本也最为重要的一点,就是构建出每位员工的工作内容时间线,通过时间线我们就可以了解到“who,when,what”,即:谁,在何时,做过什么事情。有了这些结构化的知识,如果想知道谁在做Cortana相关的项目,只需要问“Who is working on Cortana?”,EDI就能给出你想要的答案。这对构建企业智能应用具有极为重要的意义。
人工智能系统是如何抽取出工作内容以及相关项目的名称呢?
项目的名称都是语义完整的短语——例如,在“微软亚洲研究院在丹棱街5号”这句话里,“微软亚洲研究院”就是一个语意完整的短语——于是,先从企业内部的数据抽取出语意完整的短语,再从这些短语中划分出项目的名称。在微软内部,各种文档、网页等总量在千万这个数量级,而统计规则例如互信息、熵等,在数据量较大的时候可以有效地完成对短语的切分。因此,在递归神经网络(Recursive Neural Network)模型中通过后验正则化(Posterior Regularization)引入互信息、熵等统计量定义的偏序切分规则,在完成短语划分的同时,得到其对应的语意向量表示,最后通过度量语意信息来判断其是否是一个项目的名称。
有了基于企业内部和互联网大数据构建员工的职场知识图谱EDI Graph,就能让机器人个人助理EDI Bot拥有聪明的“大脑”,为用户提供贴心的服务。
 联系我们请点击:
联系我们请点击:



