本文是松子(李博源)的大数据平台发展史系列文章中的一篇,本系列以独特的视角,比较了非互联网和互联网两个时代以及传统行业与非传统行业。是对数据平台发展的一个回忆,对非互联网、互联网,从数据平台的用户角度、数据架构演进、模型等进行了阐述。
1.在互联网时代被弱化的数据模型
谈起数据模型就不得不提传统数据平台架构发展,我相信很多朋友都晓得传统数据平台的知识,其架构演进简单一句话说“基本上可以分为五个时代、四种架构”,但是到了互联网时代因为大数据快速膨胀与数据源类型多样化特点,从高阶架构上来看大约从传统数据平台第三代架构开始延续的,但是往后的发展从我自己的这一点知识上很难对互联网的数据平台做架构归类。
但是从数据平台建设与服务角色上还是有章可循的。就像上篇分享到那样,类比两个行业,互联网企业中员工年龄比非互联网企业的要年轻、受教育程度、对计算机的焦虑程度明显比传统企业要低、还偶遇其它各方面的缘故,导致了数据平台所面对用户群体与非互联网数据平台有所差异化。
传统行业与互联网行业数据平台用户特性我只选择前文章的两张图来表示
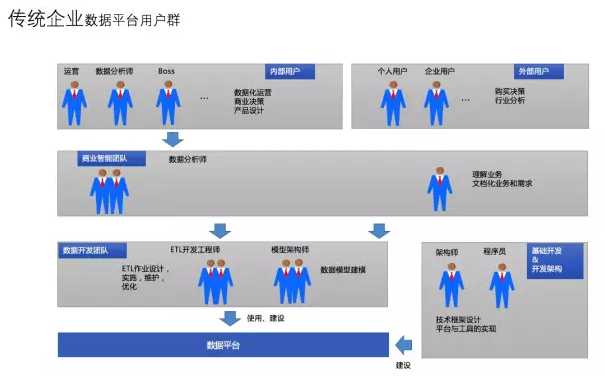
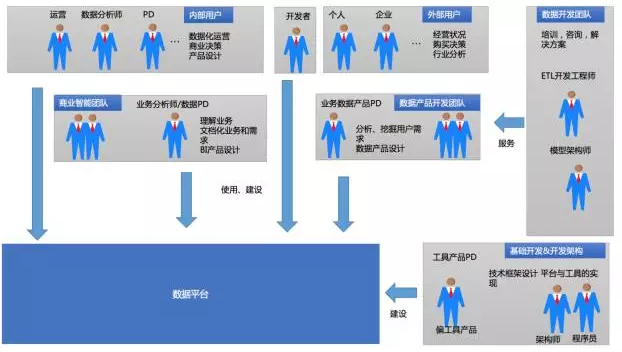
在传统数据平台要背后有一个完整数据仓库团队去服务业务方,业务方嗷嗷待哺的等待被动方式去满足。中低层数据基本不会对业务方开放,所以不管数据模型采用何种建模方式,主要满足当时数据架构规划即可。
互联网业务的快速发展使得大家已经从经营、分析的诉求重点转为数据化的精细运营上,如何做好精细化运营问题上来,当资源不够时用户就叫喊,甚至有的业务方会挽起袖子来自己参与到从数据整理、加工、分析阶段。
此时呢,原有建设数据平台的多个角色(数据开发、模型设计)可能转为对其它非专业使用数据方,做培训、咨询与落地,写更加适合当前企业数据应用的一些方案与开发些数据产品等。
在互联网数据平台由于数据平台变为自由开放,大家使用数据的人也参与到数据的体系建设时,基本会因为不专业性,导致数据质量问题、重复对分数据浪费存储与资源、口径多样化、编码不统一、命名问题等等原因。数据质量逐渐变成一个特别突出的问题。
传统企业的数据源基本来自excel、表格、DB系统等,但在互联网有网站点击流日志、视频、音频、图片数据等很多非结构化快速产生与保存。移动互联网除了 互联网那些外还含有大量定位数据、自动化传感器、嵌入式设备、自动化设备等,传统行业原有的数据平台技术对处理如此复杂而多样化的数据有些力不从心。
当数据模型逐渐被弱化后,数据架构导航图少了、难以建立业务系统与数据之间的映射与转换关系。数据描述经常不一致性。如:同名异义、同物异名。大量冗余的存 在。数据模型被弱化(数据仓库模型)是传统企业与互联网企业一个蛮大的差异。但是呢,互联网企业也有自己特点,传统行业所涉及数据模型这个领域涉及的很多 内容在互联网变成以其他的曲线救国的方式存在了。
2.在互联网曲线救国解决
回顾在传统行业数据平台中,不管两位大师争论点数据模型的设计采用那种范式(Bill Inmon的EDW的原则是准三范式的设计、Ralph kilmbal是星型结构)但是都要非常重视数据源的质量问题。所以传统行业的数据模型会全盘考虑数据质量问题,并通过数据抽样分析给出合适的清洗口径。
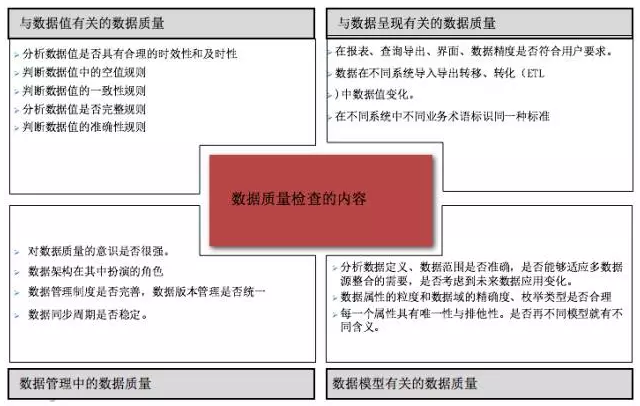
上图来自我2009年搞数据质量平台工具数据产品内容之一
但是在互联网呢,数据质量在互联网数据平台变成了一种心病。(ps:我了解过一个公司,能让数据平台+数据分析师+业务多人“对数”对一年的还是不准的)。在应对数据的质量问题,目前互联网有些做法是把数据标准化前置到业务数据产生就做,从根源上去杜绝数据质量,但是这种场景比较实用在Log 日志的数据源中,比如移动互联网最近流行的基于事件模型“Event”模型,在日志产生时就规定好存储格式。
在传统行业,目前还是以混合模型设计方式为主。在互联网的我所接触的一些业务,在参照传统数据模型方法论基础上逐步演进适合互联网数据的数据模型方法。
比如互联网金融等一些业务会参考传统金融行业对主题域的划分、OMG数据仓库元数据管理CWM模型、FSDM金融模型,再进一步考虑大数据处理特性去进行设计,所有从Hight Level 数据架构图看到主题层次划分与传统第三代数据仓库还是很多相似之处,当然模型架构也有分三层、四层、五层的。
不同的地方模型细节处理上已经完全不一样,比如数据的多样性、拉宽事实表、度量值单独存储、满足数据快速重生、维度的二次降维处理等、增加大量冗余列、增加大量派生列,结合自动化元数据来耦合、合并等相关管理。
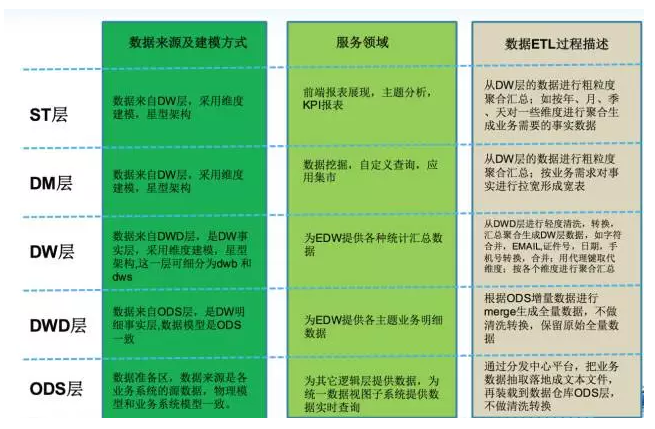
上图是支付宝非常早期数据模型▲

上图是支付宝非常早期数据模型▲
我们常提到的多维模型在大数据处理下进行了退化维度处理。大家知道Olap多维模型,随着维度的增加事实表的数据量会成几何指数暴增,即使在现有的大数据技术、新的Olap 引擎对一个Cube的数据量要求也要在时间与数据量上需要做到用户使用容忍度的平衡。
类似Olap的应用在互联网这个奇特思维土壤中我经历过一个曲线救国方式(2011-2012年时设计多维挖掘分析数据产品背后的技术就是搜索引擎实现的),现在应该也有新技术出现了来解决类似的问题。
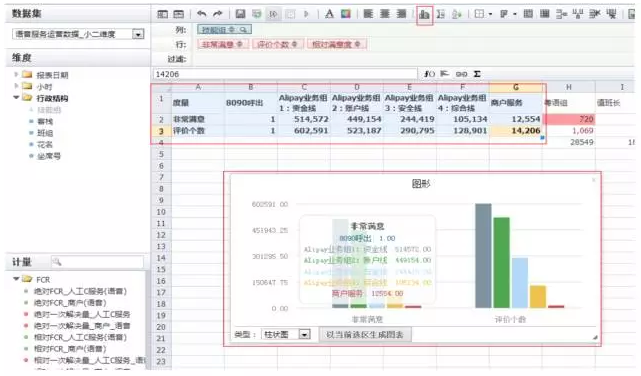
上图为2012年产品UI之一▲
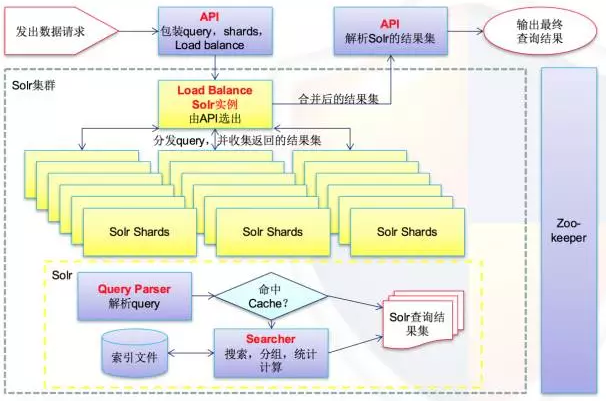
上图是2011-2012年该产品系列背后当时使用的技术▲
互联网业务特点业务垂直拆分非常细,比如一个用户注册、密码找回的流程有可能存在好几个产品负责同一个业务流程不同环节,相关的一个策略、产品feature快速迭代上线等等都要数据评估。数据从前端埋点到采集然后再由各个环节到数据平台,再有数据分析师或各业务部门去使用,基本拉长了时间周期。需求部门与实施部门能力和经验有千差万别的需求,造成了懂技术部门没有没有足够的精力完全理解业务部门奇形怪状需求,可能在各环节放缓与变的低效。
或许适合“敏捷”维度建模在当前是个不错的选择,如果一上来就想着建立一套能兼容所有数据和业务的数据模型,那就又回到传统数据仓库的建设上了,很难满足对业务变化的快速响应。互联网企业业务特点是变化非常迅速的,能稳定的业务达到65%算对数据平台是个福音了(根据对某宝宝的印象)剩余的业务变化迅速,必 然导致数据模型快速上下线。
Kimball老人家提出的维度建模(备注,在本系列发展史得第一篇有介绍)围绕业务模型能够非常直观的表达出业务的数据关系,但是在互联网NOSQL牺牲掉了关系型数据库的一致性、完整性等等很多东西。维度数据模型又基于这些大数据技术的,所以进化的更加轻量级与基于细节数据的维度退化建模(原有的缓慢变化维、快速变化维、大维、迷你维、父子维、雪花维为了适应互联网的大数据Nosql处理技术进行反规范化、化&数据冗余设计。
退化维度的反规范化设计一方面可以把一条查询语句所需要的所有数据组合起来放到一个地方存储 Key values 的方式(比如说商品有不同类型,每一种类型商品又有自己的不同属性,可以采用一对多、多对多的方式存储,例如把一个多维映射为一个Key value)。
讲到互联网数据平台就要提数据模型,提了数据模型就要提Nosql技术
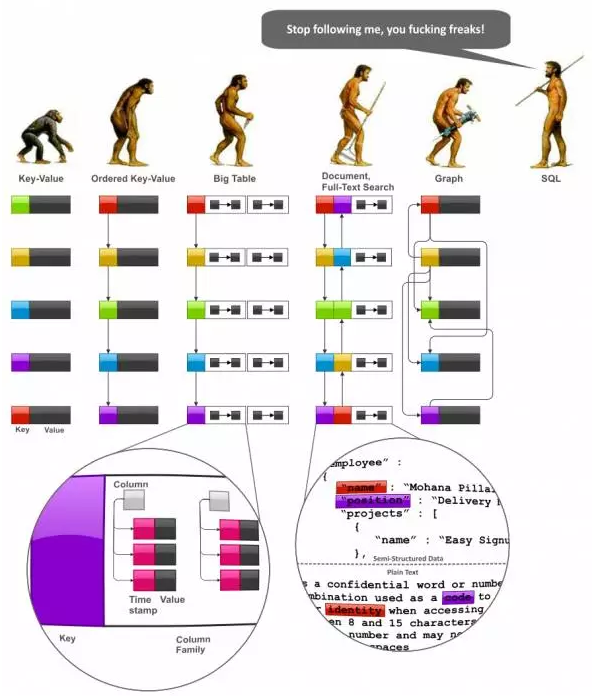
上图来自Nosql文档系列的一幅图▲
Nosql 是大数据处理的特征之一。互联网数据平台数据模型与NoSql技术还是蛮紧密的。这里有外文讲解Nosql Data modeling technigues 从技术角度讲解非常详(https://highlyscalable.wordpress.com/2012/03/01/nosql-data-modeling-techniques/)。
因为前边提到的大数据平台技术特性决定了传统edw模型、维度模型直接在互联网数据大数据平台部署或许还有“好些未知”障碍等待大家去克服。同时在传统数据建模用到的一些方法经过互联网熏陶或许演进成一种新的数据产品或方案吧。
 联系我们请点击:
联系我们请点击:



