
1.概述
Hadoop已被公认为大数据分析领域无可争辩的王者,它专注与批处理。这种模型对许多情形(比如:为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自高度动态的来源的实时信息。为了解决这个问题,就得借助Twitter推出得Storm。Storm不处理静态数据,但它处理预计会连续的流数据。考虑到Twitter用户每天生成1.4亿条推文,那么就很容易看到此技术的巨大用途。
但Storm不只是一个传统的大数据分析系统:它是复杂事件处理(CEP)系统的一个示例。CEP系统通常分类为计算和面向检测,其中每个系统都是通过用户定义的算法在Storm中实现。举例而言,CEP可用于识别事件洪流中有意义的事件,然后实时的处理这些事件。
2.为什么Hadoop不适合实时计算
这里说的不适合,是一个相对的概念。如果业务对时延要求较低,那么这个问题就不存在了;但事实上企业中的有些业务要求是对时延有高要求的。下面我就来说说:
2.1时延
Storm的网络直传与内存计算,其时延必然比Hadoop的HDFS传输低得多;当计算模型比较适合流式时,Storm的流试处理,省去了批处理的收集数据的时间;因为Storm是服务型的作业,也省去了作业调度的时延。所以从时延的角度来看,Storm要快于Hadoop,因而Storm更适合做实时流水数据处理。下面用一个业务场景来描述这个时延问题。
2.1.1业务场景
几千个日志生产方产生日志文件,需要对这些日志文件进行一些ETL操作存入数据库。
我分别用Hadoop和Storm来分析下这个业务场景。假设我们用Hadoop来处理这个业务流程,则需要先存入HDFS,按每一分钟(达不到秒级别,分钟是最小纬度)切一个文件的粒度来计算。这个粒度已经极端的细了,再小的话HDFS上会一堆小文件。接着Hadoop开始计算时,一分钟已经过去了,然后再开始调度任务又花了一分钟,然后作业运行起来,假设集群比较大,几秒钟就计算完成了,然后写数据库假设也花了很少时间(理想状况下);这样,从数据产生到最后可以使用已经过去了至少两分多钟。
而我们来看看流式计算则是数据产生时,则有一个程序一直监控日志的产生,产生一行就通过一个传输系统发给流式计算系统,然后流式计算系统直接处理,处理完之后直接写入数据库,每条数据从产生到写入数据库,在资源充足(集群较大)时可以在毫秒级别完成。
2.1.2吞吐
在吞吐量方面,Hadoop却是比Storm有优势;由于Hadoop是一个批处理计算,相比Storm的流式处理计算,Hadoop的吞吐量高于Storm。
2.2应用领域
Hadoop是基于MapReduce模型的,处理海量数据的离线分析工具,而Storm是分布式的,实时数据流分析工具,数据是源源不断产生的,比如:Twitter的Timeline。另外,M/R模型在实时领域很难有所发挥,它自身的设计特点决定了数据源必须是静态的。
2.3硬件
Hadoop是磁盘级计算,进行计算时,数据在磁盘上,需要读写磁盘;Storm是内存级计算,数据直接通过网络导入内存。读写内存比读写磁盘速度快N个数量级。根据行业结论,磁盘访问延迟约为内存访问延迟的7.5w倍,所以从这个方面也可以看出,Storm从速度上更快。
3.详细分析
在分析之前,我们先看看两种计算框架的模型,首先我们看下MapReduce的模型,以WordCount为例,如下图所示:

阅读过Hadoop源码下的hadoop-mapreduce-project工程中的代码应该对这个流程会熟悉,我这里就不赘述这个流程了。
接着我们在来看下Storm的模型,如下图所示:
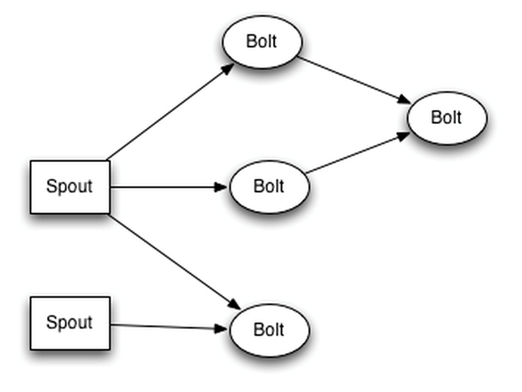
然后下面我们就会涉及到2个指标问题:延时和吞吐。
延时:指数据从产生到运算产生结果的时间。与“速度”息息相关。
吞吐:指系统单位时间处理的数据量。
另外,在资源相同的情况下;一般Storm的延时要低于MapReduce,但是
吞吐吞吐也要低于MapReduce,下面我描述下流计算和批处理计算的流程。整个数据处理流程来说大致可以分为三个阶段:
1.数据采集阶段
2.数据计算(涉及计算中的中间存储)
3.数据结果展现(反馈)
3.1.1数据采集阶段
目前典型的处理策略:数据的产生系统一般出自Web日志和解析DB的Log,流计算数据采集是获取的消息队列(如:Kafka,RabbitMQ)等。批处理系统一般将数据采集到分布式文件系统(如:HDFS),当然也有使用消息队列的。我们暂且把消息队列和文件系统称为预处理存储。二者在这个阶段的延时和吞吐上没太大的区别,接下来从这个预处理存储到数据计算阶段有很大的区别。流计算一般在实时的读取消息队列进入流计算系统(Storm)的数据进行运算,批处理系统一般回累计大批数据后,批量导入到计算系统(Hadoop),这里就有了延时的区别。
3.1.2数据计算阶段
流计算系统(Storm)的延时主要有以下几个方面:
Storm进程是常驻的,有数据就可以进行实时的处理。MapReduce数据累计一批后由作业管理系统启动任务,Jobtracker计算任务分配,Tasktacker启动相关的运算进程。
Storm每个计算单元之间数据通过网络(ZeroMQ)直接传输。MapReduceMap任务运算的结果要写入到HDFS,在Reduce任务通过网络拖过去运算。相对来说多了磁盘读写,比较慢。
对于复杂运算,Storm的运算模型直接支持DAG(有向无环图,多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出),MapReduce需要多个MR过程组成,而且有些Map操作没有意义。
3.1.3数据展现
流计算一般运算结果直接反馈到最终结果集中(展示页面,数据库,搜索引擎的索引)。而MapReduce一般需要整个运算结束后将结果批量导入到结果集中。
4.总结
Storm可以方便的在一个计算机集群中编写与扩展复杂的实时计算,Storm之于实时,就好比Hadoop之于批处理。Storm保证每个消息都会得到处理,而且速度很快,在一个小集群中,每秒可以处理数以百万计的消息。
Storm的主要特点如下:
·简单的编程模型。类似于MR降低了并行批处理的复杂行,Storm降低了实时处理的复杂行。
·可以使用各种编程语言。只要遵守实现Storm的通信协议即可。
·容错性。Storm会管理工作进程和节点故障。
·水平扩展。计算是在多个线程,进程和服务器之间并行进行的。
·可靠的消息处理。Storm保证每个消息至少能得到处理一次完整的处理,使用MQ作为其底层消息队列。
·本地模式。Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
最后总结:Hadoop的MR基于HDFS,需要切分输入数据,产生中间数据文件,排序,数据压缩,多分复制等,效率地下。而Storm基于ZeroMQ这个高性能的消息通讯库,不能持久化数据。
专家说
雅虎云平台组的副总裁HariVasudev解释说,Hadoop在处理大量结构与非结构数据上是“非常有效的”。它适用于在传统数据仓库中对即时查询需求的支持,但不能取代针对有低潜在因素需求的传统商业智能(BI)功能的关系型数据库管理系统(RDBMS)的部署。
Vasudev曾指出Hadoop的工作量很大,注意到网络是最难确定的变量。“关键是要购买足够的网络容量,让所有节点在集群以合理的速度和合理的成本上互相交流,”他说。
Hoosenally还指出,企业在利用Hadoop上面临着“急剧上升的学习曲线”,而这将使与遗留的IT系统的整合“较为困难”。
更有甚者,当前在如何启动和确保有效使用开源框架上缺乏文档和信息,他补充说。
他又指出,招聘具有该领域专业知识的合适人才是另一种挑战。
互联网数据中心(IDC)亚太区联合副总裁PhilipCarter在早先的一份报告中强调了数据人才的缺乏。他举例说,在亚洲的公司对大数据以及IT部门应该如何接近它的理解上层次较低。即使在这个领域有更多知识的IT领导人也不能确定管理信息采集所需技能的种类,该分析师说。
 联系我们请点击:
联系我们请点击:



