优酷视频搜索是文娱分发场最核心的入口之一,数据源多、业务逻辑复杂,尤其实时系统的质量保障是一个巨大挑战。如何保障数据质量,如何衡量数据变化对业务的影响?本文会做详细解答。
一、现状分析
搜索数据流程如下图所示,从内容生产到生成索引经历了复杂的数据处理流程,中间表多达千余张,实时数据消费即消失,难以追踪和复现。
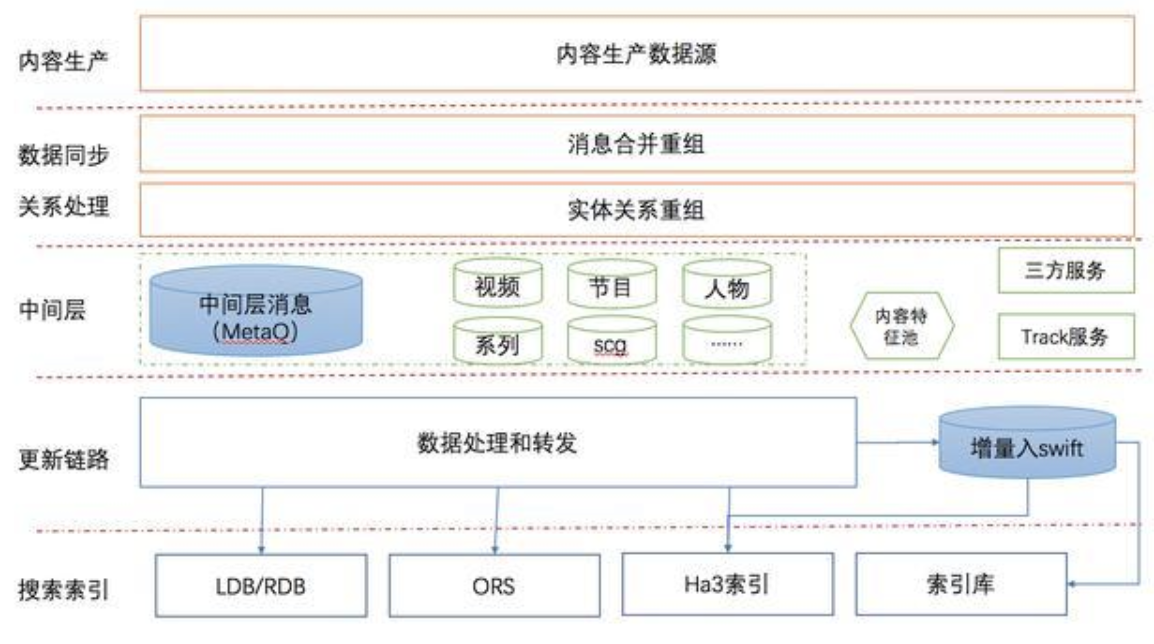
从上图可以看出,整个系统以实时流模式为数据流通主体,业务层面按实体类型打平,入口统一分层解耦,极大的增加了业务的实时性和稳定性。但是另一方面,这种庞大的流式计算和数据业务系统给质量保障带来了巨大的挑战。如何从 0 开始,建设实时数据的质量保障体系,同时保证数据对搜索引擎业务的平滑过渡?这是我们面临的挑战。
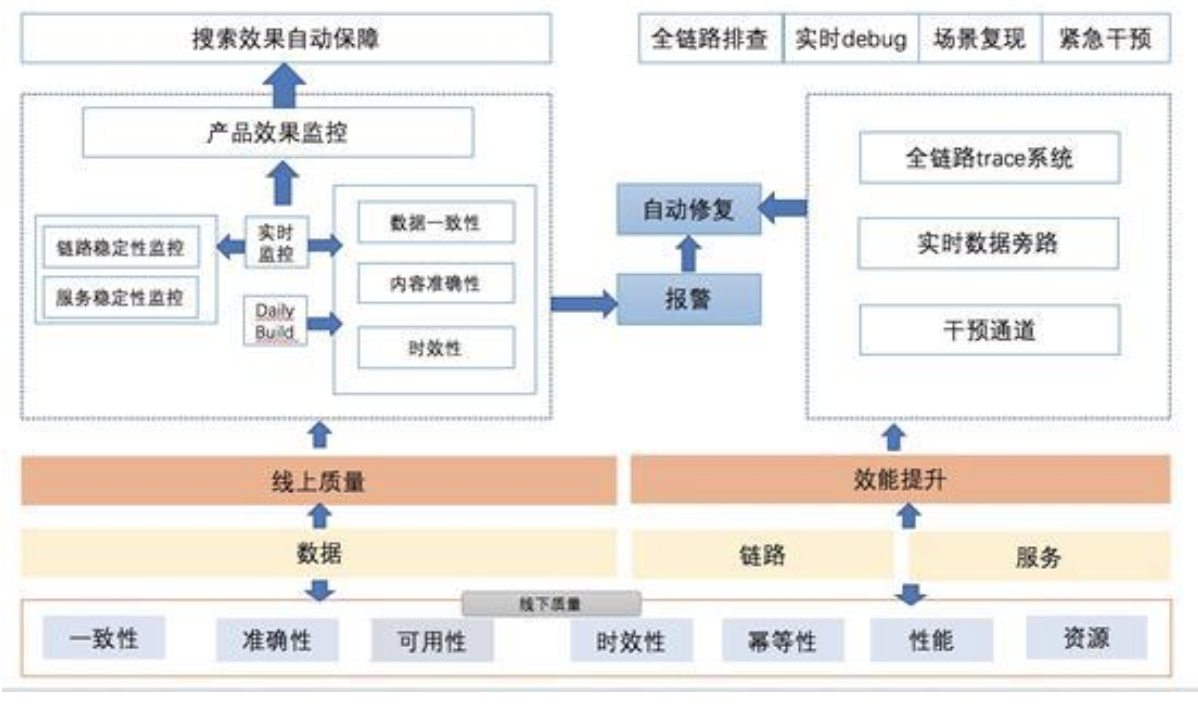
二、实时数据质量保障体系方案
质量保障需要透过现象看本质。通过对架构和业务的分析,可以发现整个流式计算的业务系统有几个关键点:流式计算、数据服务、全链路、数据业务(包括搜索引擎的索引和摘要)。整体的质量诉求可以归类为:
基础数据内容质量的保障
流式链路的数据正确性和及时性保障
数据变化对业务效果的非负向的保障
结合线上、线下、全链路闭环的理论体系去设计我们的整体质量保障方案,如下图所示:
三、线下质量
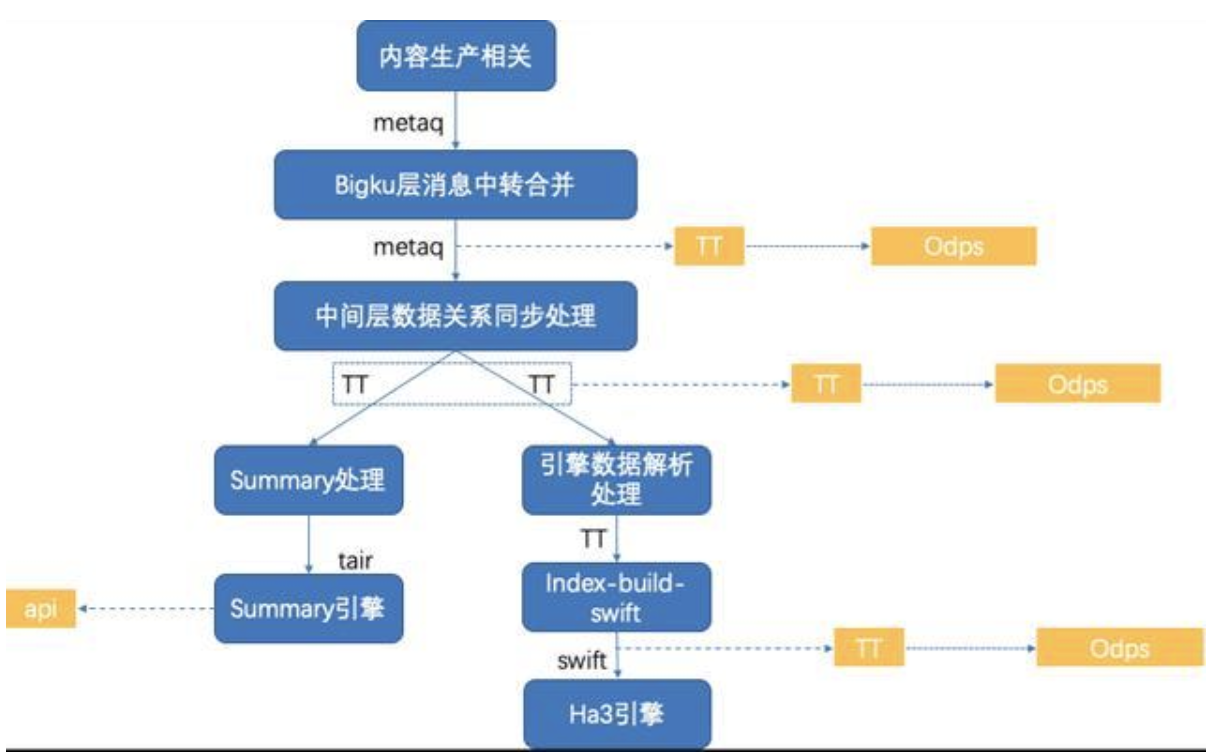
1.实时 dump
数据测试包含链路节点比对、时效性、正确性、一致性、可用性等方面,依托于阿里技术资源设计实时 dump 的方案如图:
2.数据一致性
一致性主要是指每个链路节点消费的一致性,重点在于整体链路的各个节点的数据处理消费情况保持一致,通过对数据消费的分时分频率的比对完成一致性验证。方案如下图:
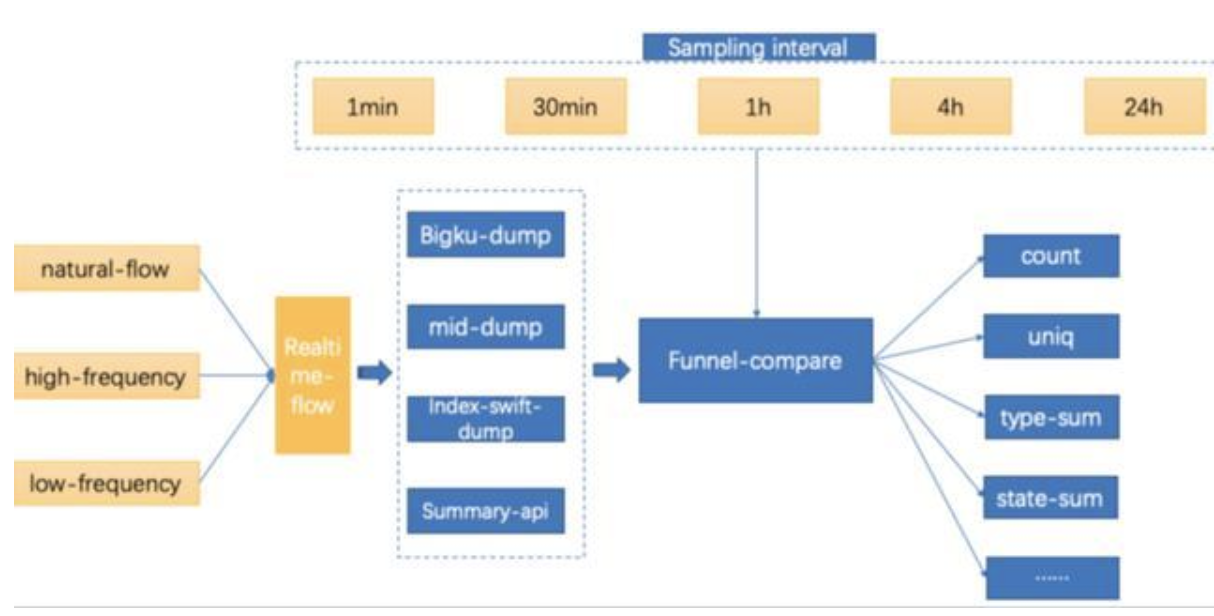
我们采取不同的数据流频率输送给实时链路进行消费,利用各层的 dump 机制进行数据 dump,然后取不同的抽样间隔对 dump 数据计算分析,分为三种不同的数据频率模式:
natural-flow:自然消费的数据流,是源于线上真实的数据消息通道,即自然频率的数据消费,以该模式进行测试更贴合实际业务情景;
high-frequency:高频数据流,采用超出真实峰值或者其他设定值的数据频次输送给实时消费链路,在压测或者检测链路稳定性中是一个常用的测试策略;
low-frequency:低频数据流,采用明显低于真实值或者特定的低频次数据输送给实时消费链路。如果数据链路中有基于数据量的批量处理策略会暴露的比较明显,比如批量处理的阈值是 100,那么在业务低峰时很有可能达不到策略阈值,这批数据就会迟迟不更新,这个批量处理策略可能不是合理。同时低频次的消费对于实时链路处理的一些资源、链接的最低可用度这些层面的检查也是有意义的。
3.数据正确性
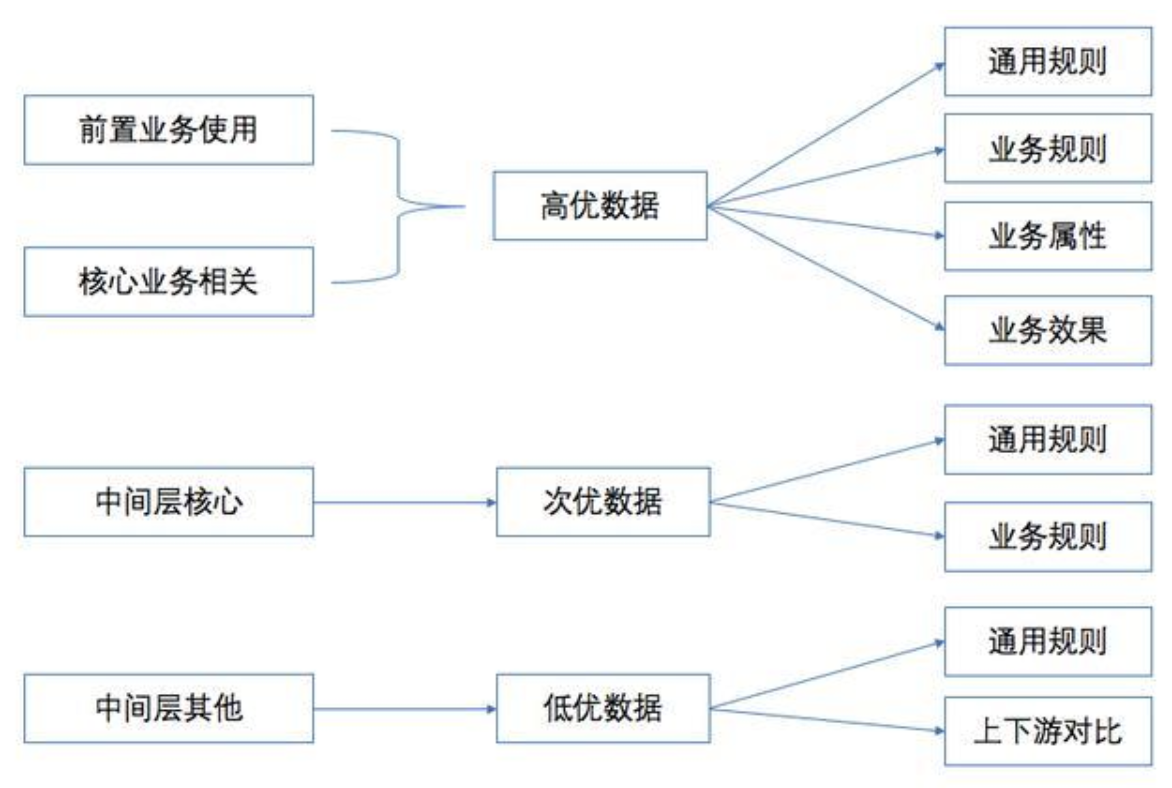
数据正确性是对于数据内容的具体值的检查,总体原则是:
首先,高优保障影响用户体验的数据;
其次,保障业务层直接使用的核心业务相关的数据内容;
再次,中间层的核心业务相关数据由于不对外露出,会转换成业务引擎需要的最终层的业务数据。所以中间层我们采用通用的规则和业务规则来做基础数据质量保障,同时对上下游数据内容变化进行 diff 对比,保障整个流程处理的准确性。
4.数据可用性
数据可用性指的是数据链路生产的最终数据是能够安全合理使用的,包括存储、查询的读写效率、数据安全读写、对不同的使用方提供的数据使用保持一致性等。
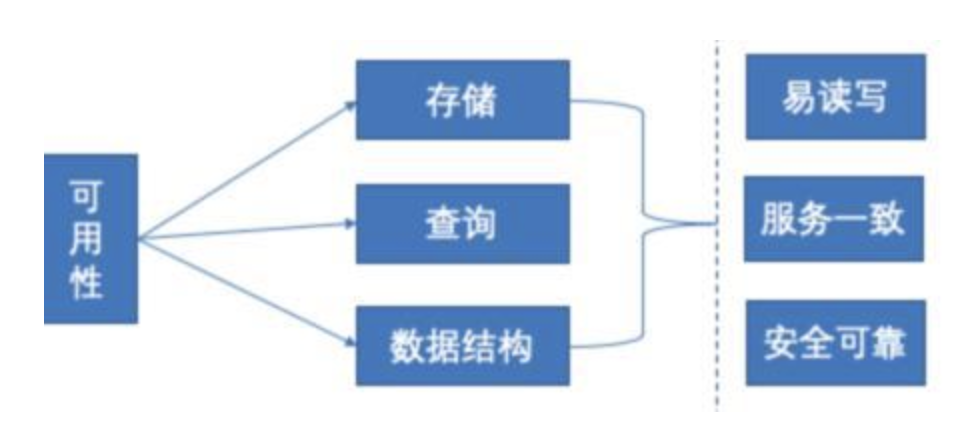
可用性保障主要关注数据的存储、查询、数据协议(数据结构)三个大的维度,衡量的标准重点关注三个方面:
易读写:数据的结构化存储和写入必须是高效合理的;
服务一致:数据在结构化存储后,对外提供的服务有很多种,比如 PB 协议、API、SDK 等,需要根据业务去考量。比如 SDK、PB 等对外提供使用的方式会涉及协议版本,不同的版本可能数据结构不一致导致对外使用的数据不一致性;
安全可靠:重点关注存储稳定、可靠、高效,兼顾效率和稳定性,同时更要关注安全性,防范随意改写数据、恶意 dump 等严重影响线上数据使用安全的风险。
5.时效性
由于实时链路的流式特性和多实体多次更新的特性,在测试时效性时核心问题有两点:
如何去跟踪确定一条唯一的消息在整个链路的消费情况;
如何低成本获取每个节点过程的数据链路时间。
我们抽象出一个 trace+wraper 的流式 trace 模型如下图:
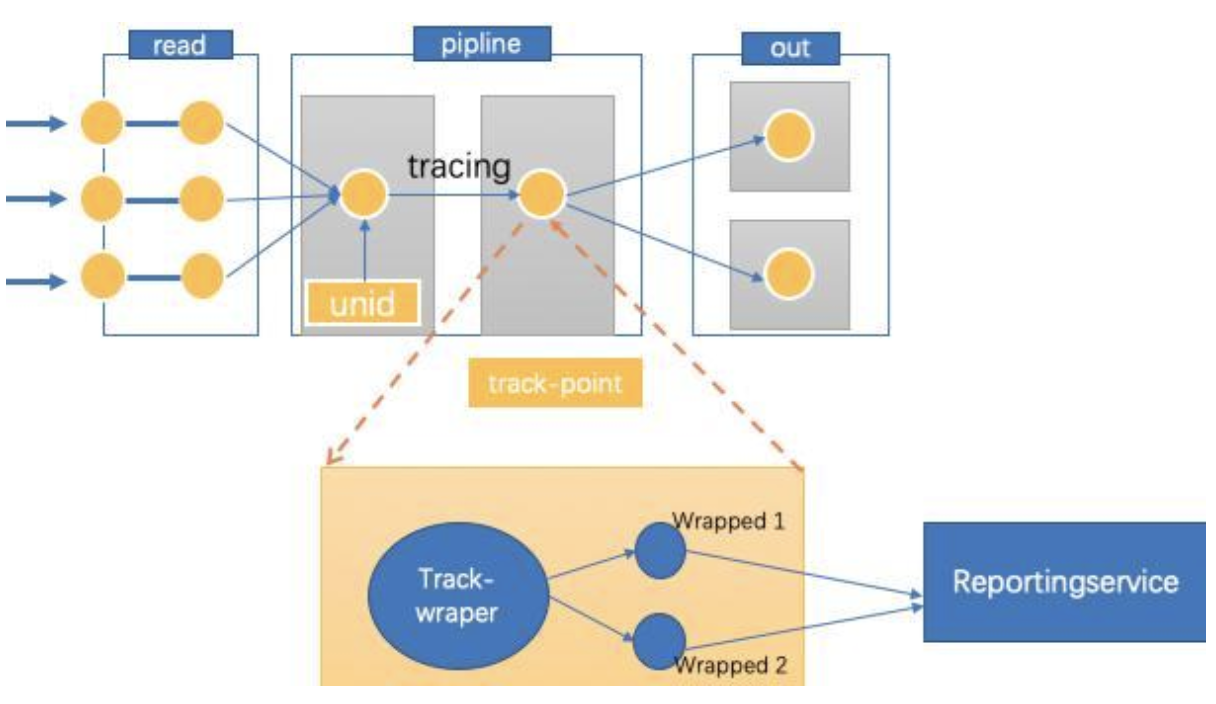
获取链路过程的每个节点的时间,包括传输时间和处理时间。对于 track-wraper 需要约定统一的 track 规范和格式,并且保证这部分的信息对业务数据没有影响,没有增加大的性能开销。如下图,我们最终的信息中经过 trace&track-wraper 带出来的 trak-info,采用 json 格式方便 track-info 的扩展性。
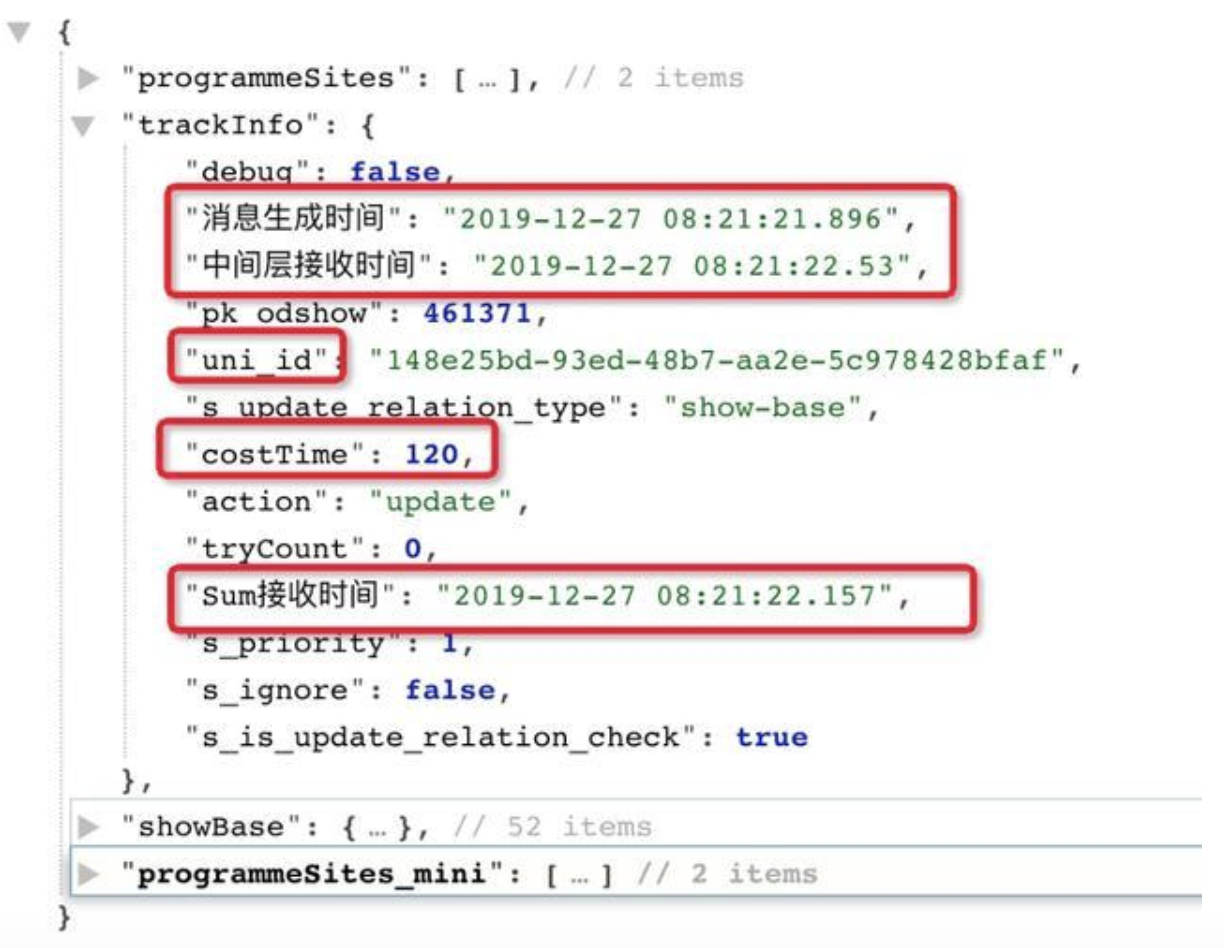
这样就很容易获取到任意信息,计算每个节点的时间:
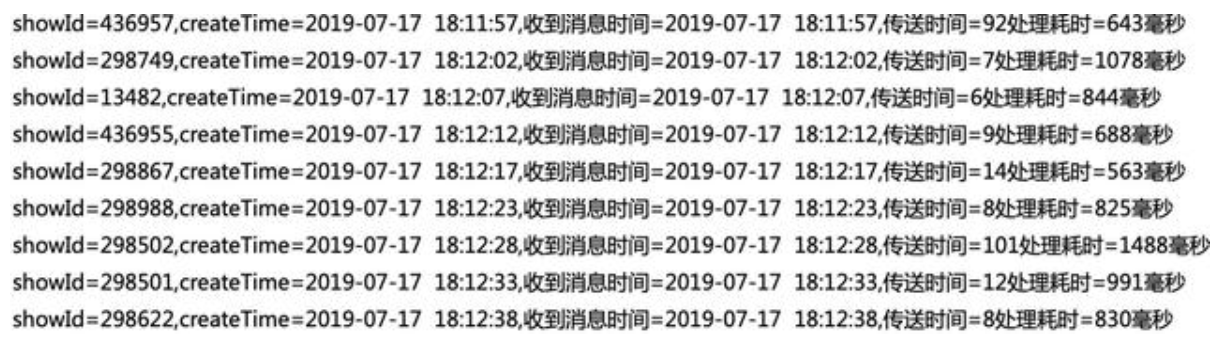
我们也可以通过抽样计算一些统计指标衡量时效:
对于时效性有明显异常的数据可以筛选出来,进行持续优化。
6.性能测试
实时数据链路本质是一套全链路数据计算服务,所以我们也需要测试它的性能情况。
第一步,我们先具体化全链路的待测系统服务
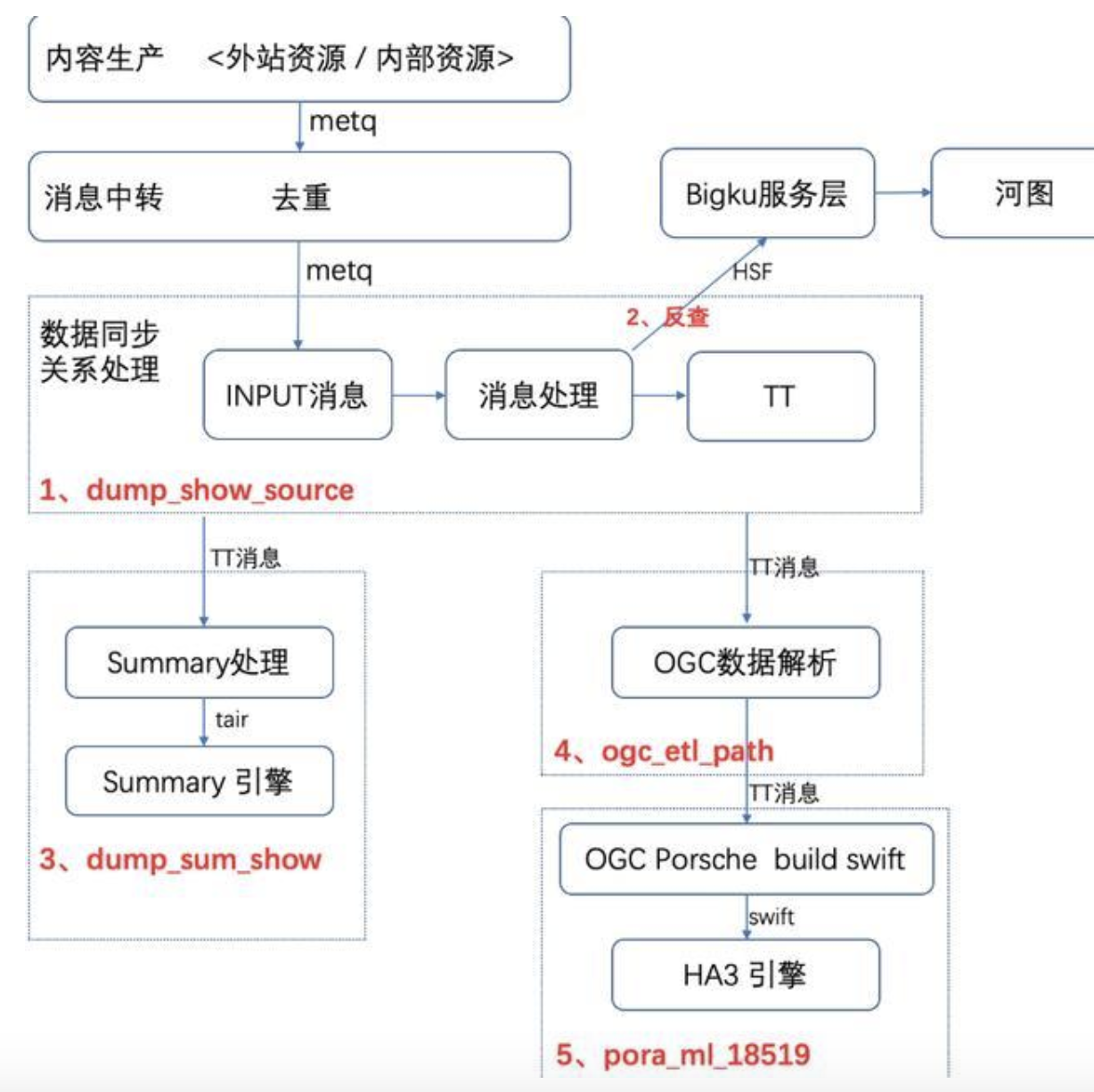
包括两部分的性能,Bigku 的反查服务,即 HSF 服务,再就是 blink 的计算链路节点。
第二步,准备数据和工具
压测需要的业务数据就是消息。数据准备有两种方式,一种是尽可能模拟真实的消息数据,我们只要获取消息内容进行程序自动模拟即可;另外一种会采用更真实的业务数据 dump 引流,进行流量回放。
由于数据链路的特性,对压测链路施压就是转成发送消息数据,那么如何控制数据发送呢?有两种方式:第一种我们开发一个发送消息的服务接口,转变成常规的接口服务压测,然后可以采用阿里的任何压测工具,整个测试就变成常规的性能测试;第二种我们可以利用 blink 消息回追的机制,重复消费历史消息进行压测,不过这种方法有弊端,无法控制消息的频率。
7.压测和指标收集
根据业务情况来收集指标,指标包括服务本身的指标和资源指标,可以参考我们的部分性能测试报告示例(数据有截断):
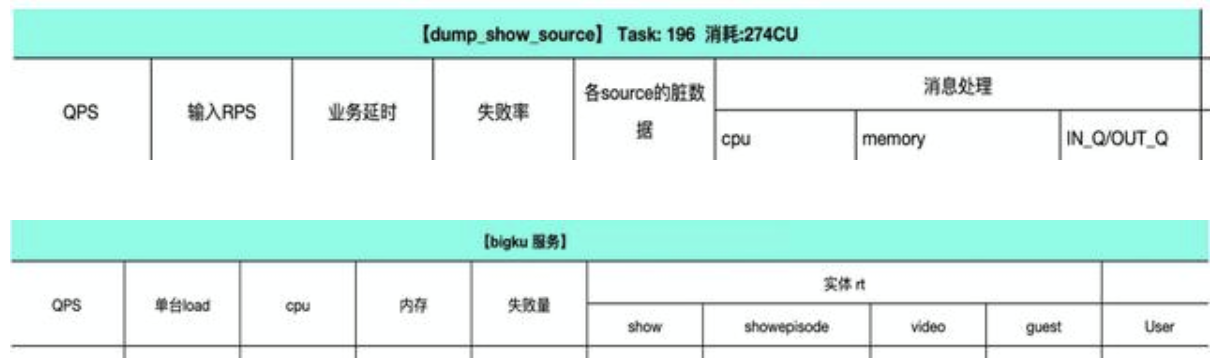
四、线上质量
1.服务稳定性保障
稳定性包括两个层面,一是实时计算任务链路的每个节点的稳定性,二是内置服务的稳定性。
2.实时计算
由于实时计算采用全 blink 的计算方式,我们可以利用 blink 系统本身的特性来做任务的监控。每个节点的任务都需要配置稳定性指标的监控,包括 rps、delay、failover 等。效果示例如下:
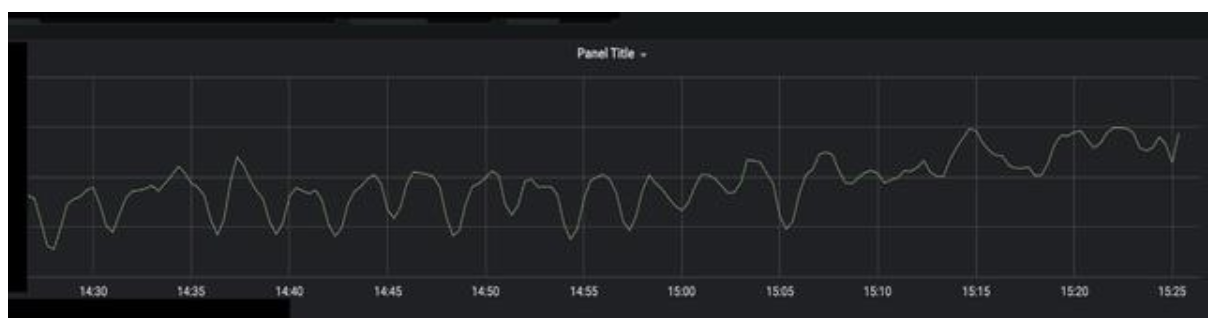
3.实体服务
实体服务是 HSF 服务,采用阿里统一的监控平台来完成整体服务能力的监控,示例如图:
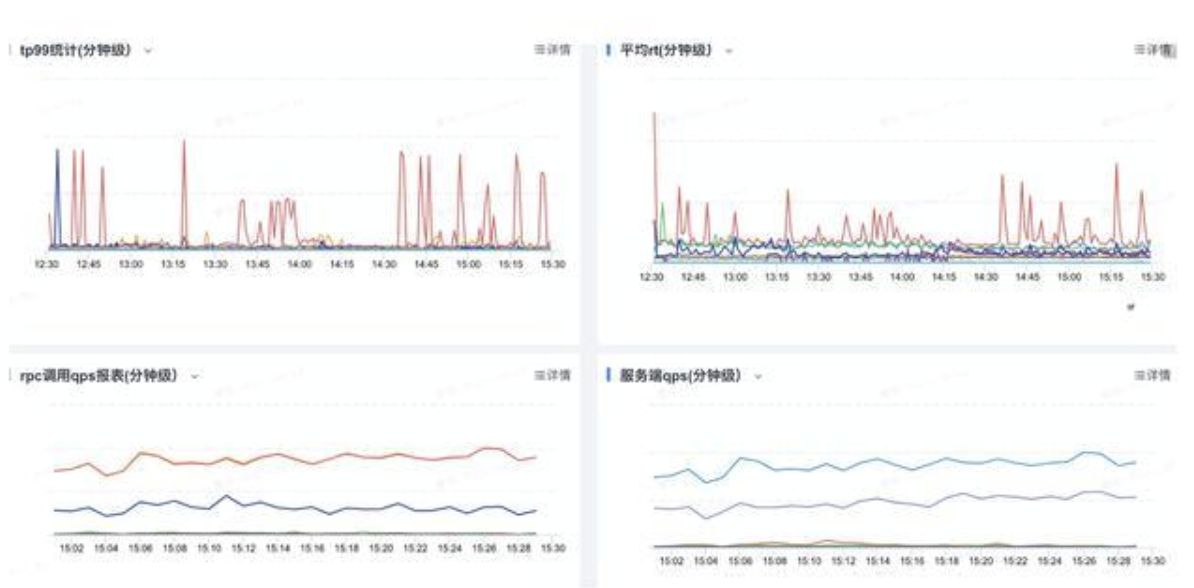
整体指标包含以下内容:
4.数据消费保障
在数据消费层面,重点关注每个链路层级的消费能力和异常情况。基于积累的 track-report 能力进行数据统计,结合平台完备的基础能力来完成消费保障。分为两层:
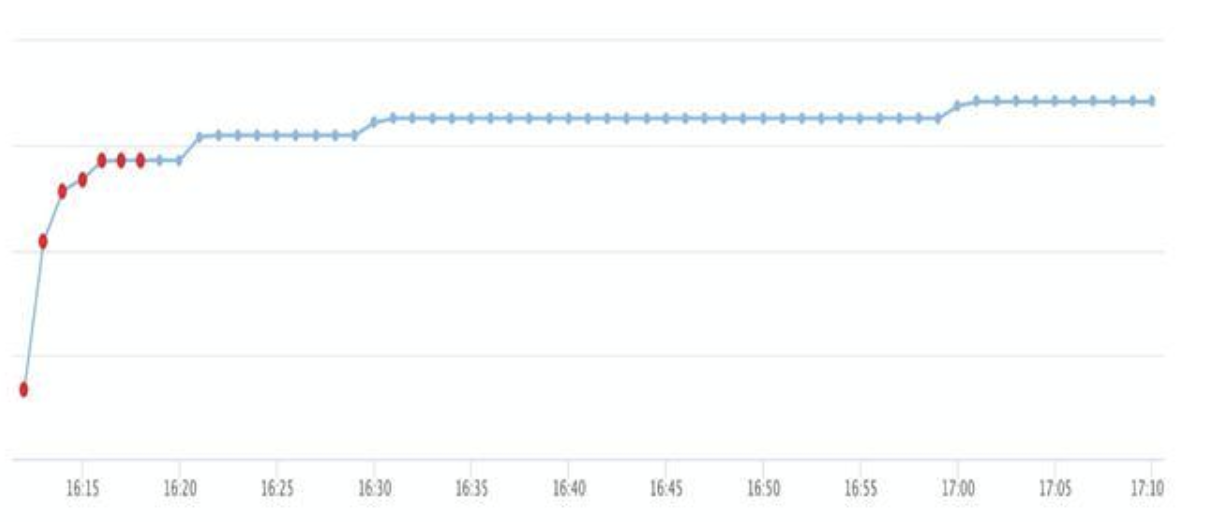
核心层:消息出口的实体消息统计监控,包括整体数量和消息内容分类统计监控。如图示例:

中间层:包括每个实体消息处理的 accept,处理逻辑层的 success、fail、skip 指标,便于我们实时知晓每个链路层收到的消息、成功处理、错误和合理异常等消费能力情况。如图示例:
5.数据内容保障
数据内容层,建设综合数据更新、数据内容检查、业务效果三位一体的精准数据检查,达到数据生产、消费、可用性的闭环检测,如图所示:
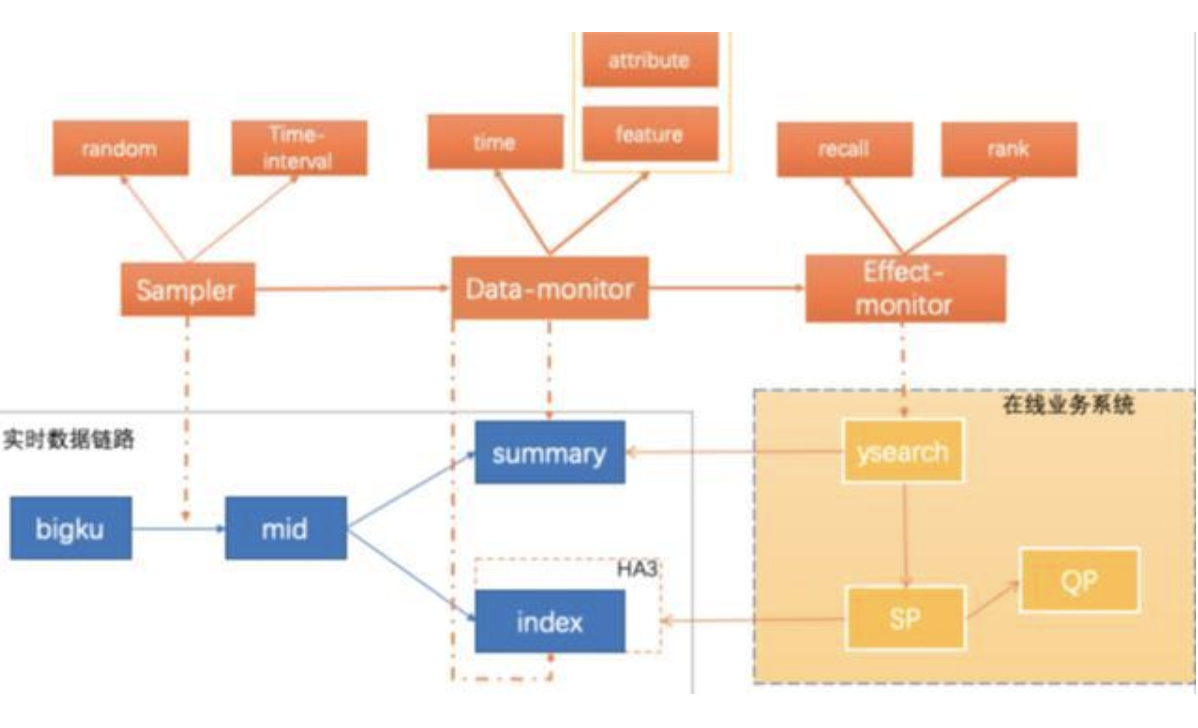
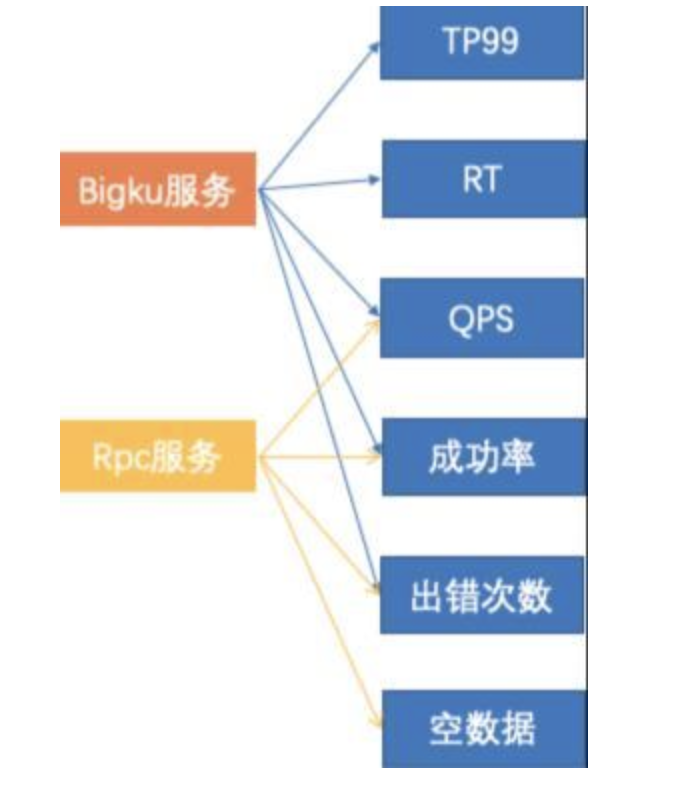
从图中可以看出,我们数据内容保障分为三部分:
1)sampler:抽样器,通过 blink 实时消费消息在链路中抽取待测数据,通常是只抽取数据 ID;抽样策略分间隔和随机两种。间隔策略就是取固定时间间隔的特定数据进行检查;随机则根据一定的随机算法策略来抽样数据进行检查。
2)data-monitor:是做数据内容检查,包括更新时效性和数据特征属性检查。
3)effect-monitor:数据正常更新之后,对在线业务实时产生的效果影响进行检查,检查的核心点包括搜索的两大基本效果——召回和排序,以及用户体验相关的数据属性的检查。
部分数据实时效果示例图:
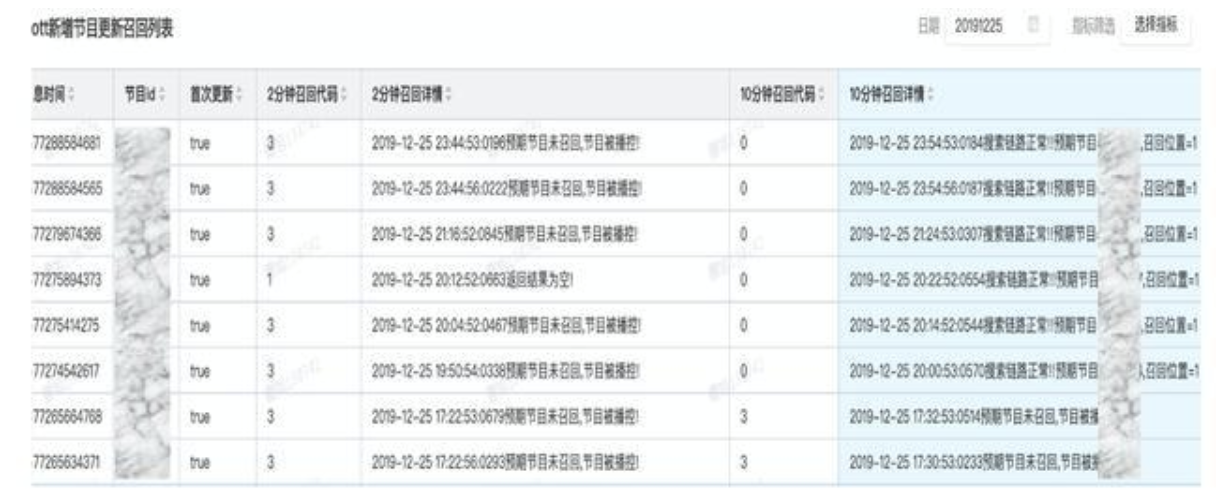
6.实时干预与自动修复
实时干预通道,如下图:
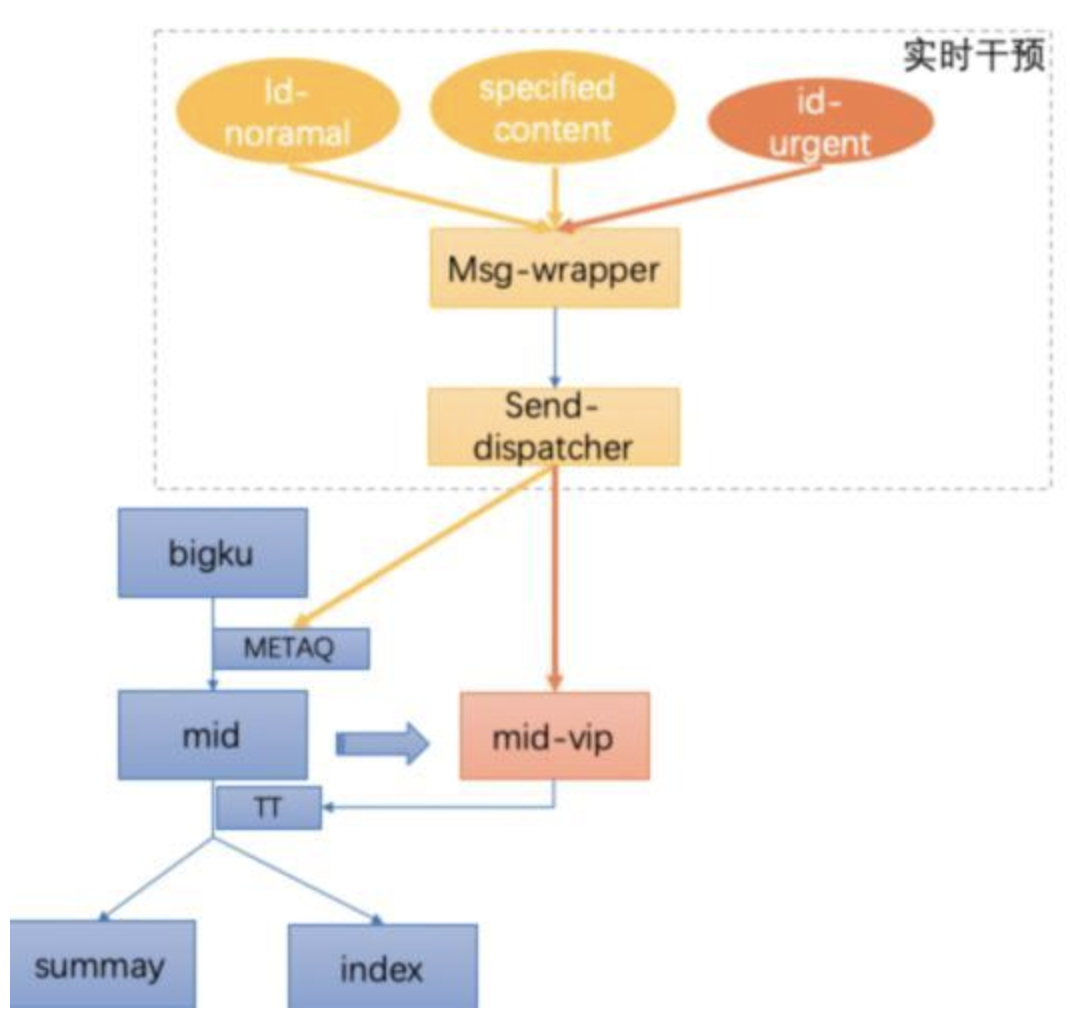
实时干预系统会根据不同的干预需求,对消息内容和干预机制进行消息组装和通道分发。
1)当主通道业务链路正常时,若需要强制更新一个 ID 维度的数据,只需要输入 ID 走正常主链路更新即可。
2)当需要强制干预某些具体的数据内容到指定的消息通道时,则可进行数据内容级别的更详细的精准干预。
3)紧急强制干预,是指当主链路中间层处理有较大延迟或者完全阻塞时,会造成下游业务层数据无法正常获取输入。通过主逻辑全 copy 的机制建立了一个 VIP 的消息通道,通过 VIP 通道去直接干预出口消息,保证业务数据正常能进行优先更新。
五、质量效能
效能层面主要指:研发能快速自测上线,线上问题能高效排查定位这两个维度,以期达到保证快速迭代、节省人力投入的目标。所以我们提供了实时 debug 和实时全链路 trace 透视两大提效体系。
1.实时 debug
实时 debug 是基于实时消息通道能力和 debug 机制建立的一套服务,在研发自测、问题复现等场景有很大用途,可以通过 debug 模式详细了解链路的业务层处理细节,业务层只需要按数据需求自主定制 debug 内容,无需其他接入成本,具备很强的通用性和扩展性。
平台效果图:
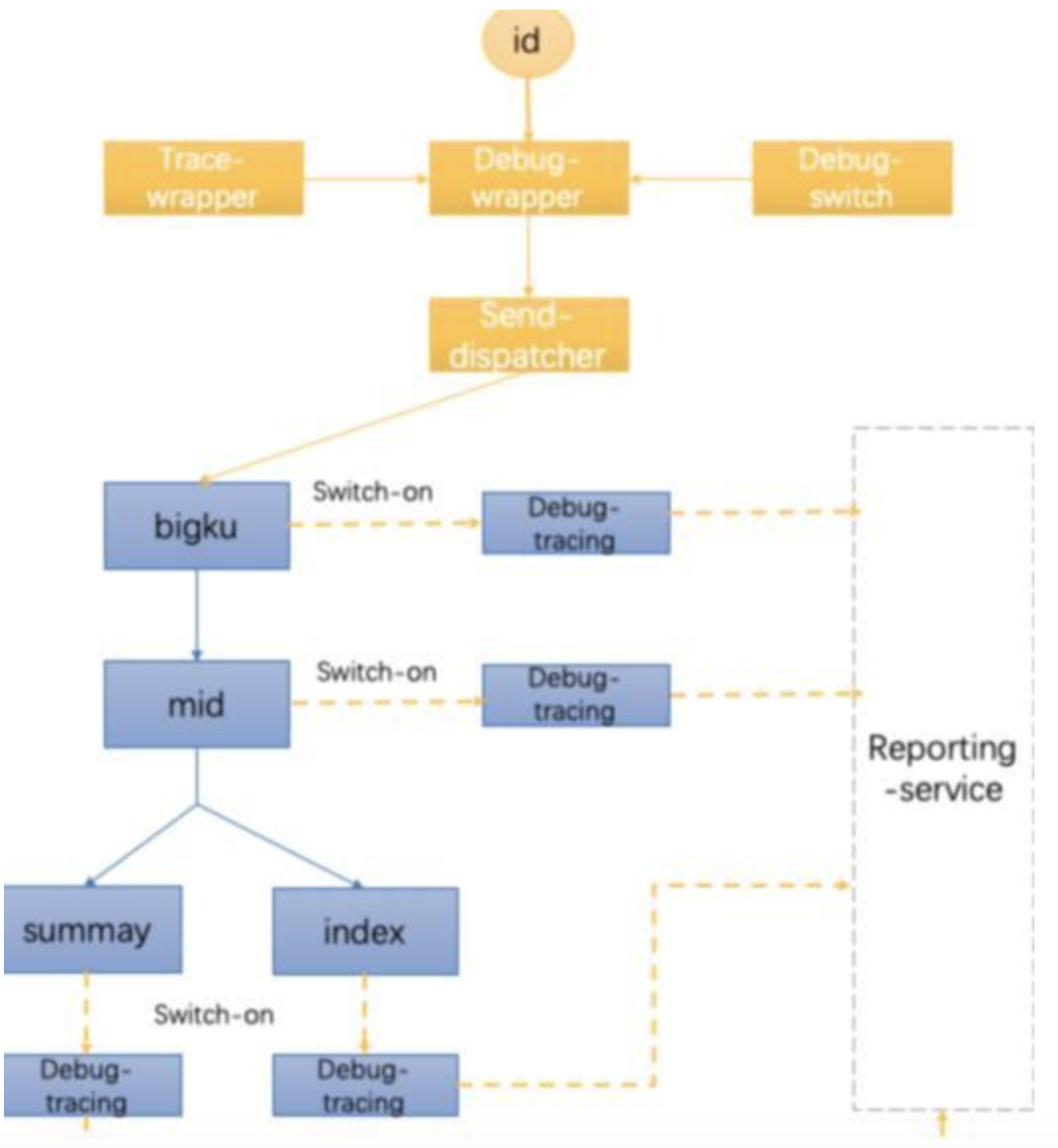
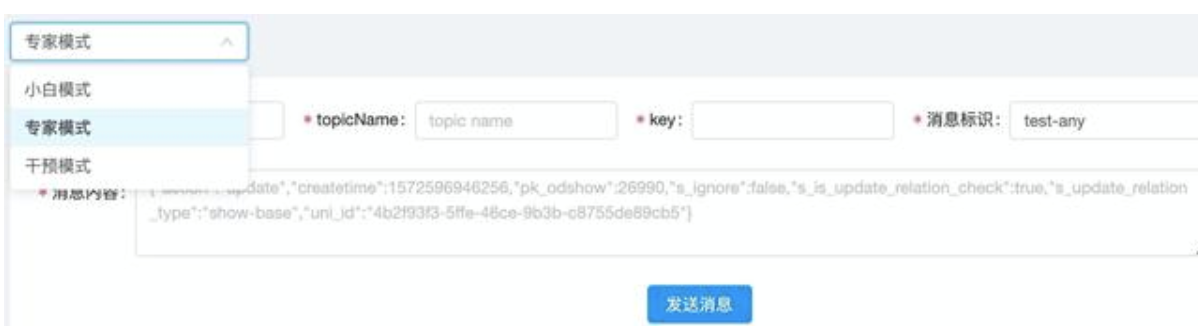
填入节目 ID,发送消息就会自动进入实时 debug 模式。
同时还配备了指定消息内容的专家模式,方便研发进行单独的消息内容制定化测试和干预。
2.全链路 trace
我们提炼了一个全链路实时 trace 的通用模型,同时做更精细定制化的 trace 机制。结合实时业务链路逻辑视图,来看下 trace 的系统实现:

链路层视角,目前整体分为 4 个业务块,数据流按顺序进行展示:
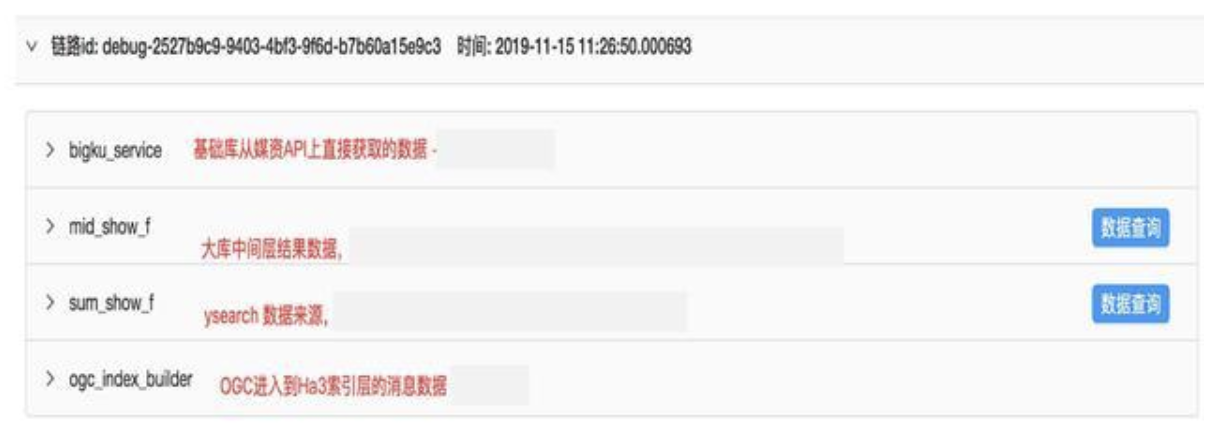
1)bigku_service 展示了当时消息的镜像数据

2) mid_show_f 为算法层面的基础特征,即一级特征,包含了业务信息和系统信息(工程关注的指标数据,主要用来指导优化)。

3)sum_video_f 和 ogc 属于搜索链路上的数据,一般在节目里面会有一些较为复杂的截断逻辑,通过字典表的形式提供数据层的透视视角,可以看到链路的全部信息。
六、产品体验实时自动化保障
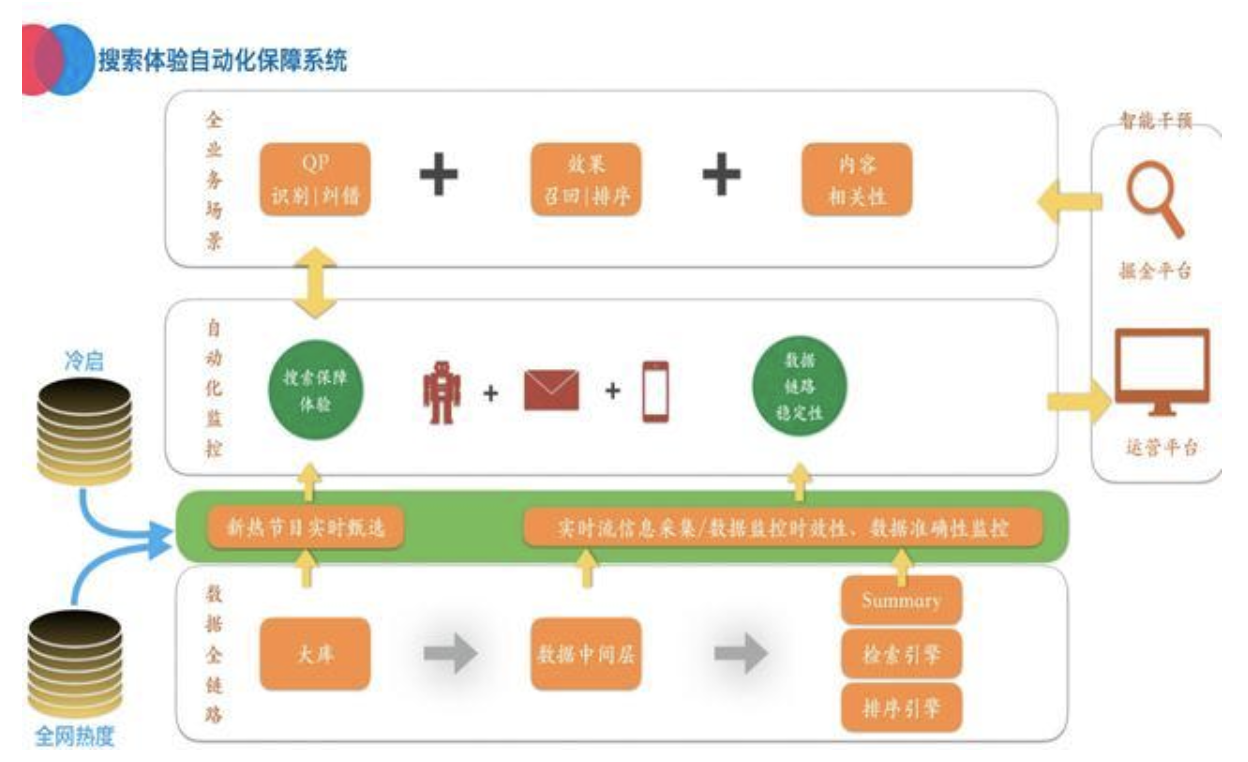
我们在实时数据内容质量方面做了融合效果监控的质量方案,建立了实时发现问题、实时定位、实时修复的闭环链路效果保障体系,起到了很好的效果。体系方案如下图:
 联系我们请点击:
联系我们请点击:



