为什么要学习爬虫?
人们最初,信息获取的方式单一,但是获取信息的准确性更加的高。互联网时代,亦是大数据时代。新时代的数据有以下几点基本特征,数据量大、类型繁多、价值密度低、速度快、时效高。所以,我们在获取信息的时候,往往会得到很多的废物信息。就像我想长胖,打开百度一搜,各种各样的内容都会有,甚至有一半的广告。这就是信息量的庞大,不利于我们对信息的分析利用。
为此,爬虫技术就诞生了。来自百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。爬虫技术就是为了更好给我们提供数据分析。
Python是爬虫最强大的语言要掌握爬虫这个技术,有很长的路要走,主要会用到:
1. Python基础语法学习(基础知识);
2. HTML页面的内容抓取(数据抓取);
3. HTML页面的数据提取(数据清洗);
4. Scrapy框架以及scrapy-redis分布式策略(第三方框架);
6. 爬虫(Spider)、反爬虫(Anti-Spider)、反反爬虫(Anti-Anti-Spider)之间的斗争。
爬虫分类
爬虫通常分为以下几类:

基本思路
爬虫的基本思路:
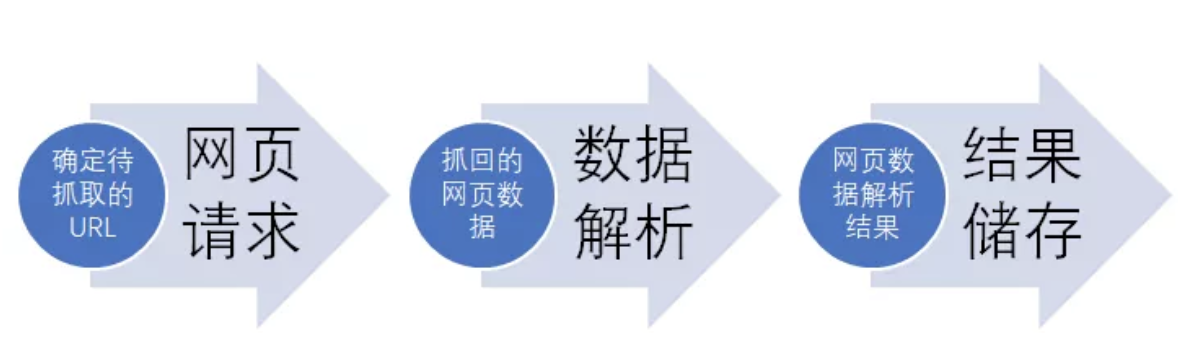
示例
import requests
from bs4 import BeautifulSoup
#确定待爬取url
url="http://www.mafengwo.cn/wenda/ "
#网页请求
response=requests.get(url)
response.encoding='utf-8'
html=response.text
#问答标题提取
soup=BeautifulSoup(html,features="lxml")
title=soup.select('div class').get_text()
#结果存储
with open('topic.txt','w',encoding='utf-8')as f:
f.write(title)
附:
Python爬虫涉及的第三方库:Beautiful Soup。关于该库的基本知识及安装方法,详见同期文章《人工智能|库里那些事儿》
 联系我们请点击:
联系我们请点击:



