数据分析对于运营来说是一个数据抽象的过程。
现实情况是连续的、复杂的、互相影响的,而数据抽象的过程,就是将这些复杂多变的现实情况简化为数字量,搭建数据模型,计算相关因子,推断事件归因,并推进自身改进优化。
由于现实的复杂性,我们作为产品、运营或者数据分析师,在实际问题处理时,就需要做归因分析,需要屏蔽其他因子的干扰,因此我们常常使用用户分群。
分群后,我们的用户群可能简化为:
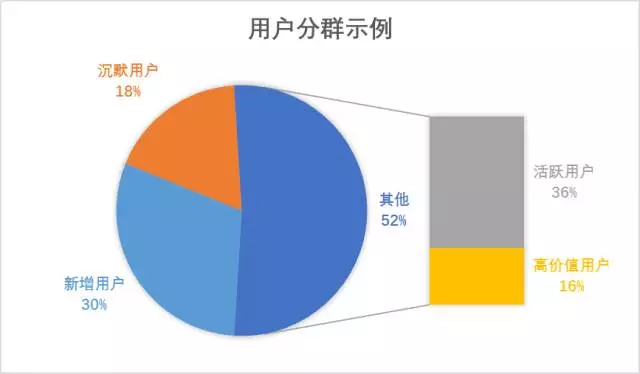
在每一个分群下,我们可以简化地对比某个因素对关键路径或者关键指标的影响因素。
分群是手段,是工具,简单来说,分群分析就是通过聚类的方式,把相似的人群合并,考察同一事件或同一指标在不同人群上的表现,以推断并定位对该事件/指标有明显影响的因子。
我们将用户精细分群与用户画像结合起来,助力精益化运营的深度与精度。
细分目标人群,结合用户画像的实践
那么,用户分群与用户画像如何结合使用?
接下来,我们举个App案例进行说明:
某电商App,现在面临的问题是用户成交量较低,与投放推广的成本相比,ROI较低。
这个问题,我们应该如何分析?
首先,我们想看看成交的这部分用户与大盘用户之间有什么区别。我们在用户中选出成交的用户,建立用户群对比大盘用户。
这里,我们需要使用MTA自定义事件。
设置“付款成功”为一个自定义事件,然后使用MTA中的用户分群功能,将自定义事件中满足“付款成功”的用户群筛选出来,命名为“成交用户”;我们还可以设置一个叫做“高价值用户”的用户群,将“付款成功”且付款金额>=100的用户筛选出来。
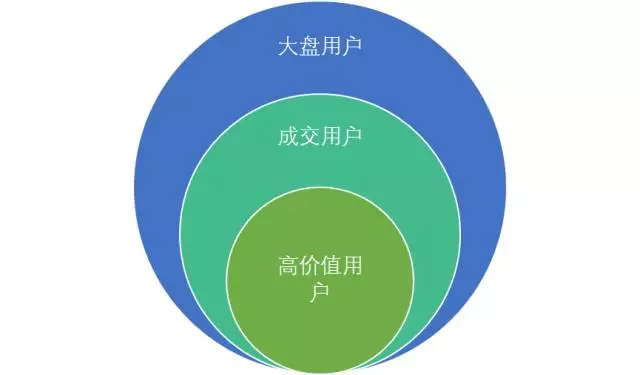
此处定义高价值用户为成交单价>100元的用户。
1.用户分群分析
得到了三个用户群之后,我们使用数据分析工具,比如腾讯移动分析MTA,对比这三个用户群特点间的区别。
以下为三个用户群特征的对比:


从图中我们可以发现,大盘用户中男性较多,但实际成单与高价值用户中,都是女性偏多,且此部分用户对购物类App、金融类App的兴趣要明显高于大盘用户,表现出了较强的消费能力。
现在我们的问题是投放回报率较低,ROI不符合预期。
那么,我们可以初步判断,可以优化的有以下两个方向:
用户引流渠道可能有问题,需要调整渠道引流策略,包括渠道选择、人群针对性优化等,引入与消费行为匹配的新用户群,提高销售量;
商品定位的调整:现有产品对男性的吸引力不足,导致大量大盘用户并没促成成单,这也是导致ROI较低的另一方面原因,可能需要调整的包括商品品类、商品推荐等;
其中,第一种优化方式的见效周期较短,而第二种调整方式相对影响层面较大、周期较长。我们优先实践第一种优化方式,以调整渠道引入流量为主,优化引入人群的匹配程度,实现提高ROI的目标。
后续还需要斟酌是否需要优化产品定位,比如打造针对男性的亮点频道,进行产品改善迭代。
2.渠道优化策略
那么,渠道应该如何做改善?我们先对单周渠道引入量的数据,进行初步评估。
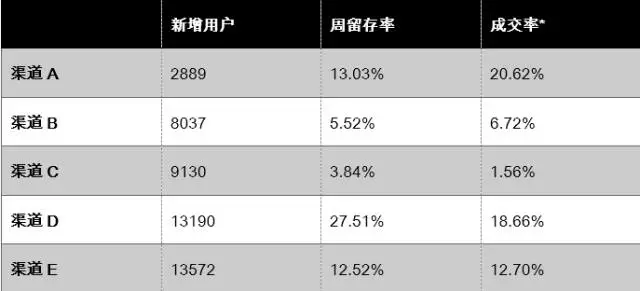
成交率数值应用的是漏斗模型的渠道筛选功能
此处渠道只列了5支较典型的渠道样本数据,实际渠道分布更多
从图表上看,我们当前主要的流量渠道是渠道D与渠道E,而且渠道D的留存率很高,可以认为是我们的优质渠道。
但从成交上看,我们认为渠道A其实有很大的潜力,虽然现在的引入量较小,但与成交人群重合度较高,考虑到A渠道的获客成本低于渠道D,加大投放之后很可能会有一个不错的收益,能够实现我们提高ROI的目标。
3.渠道人群画像验证
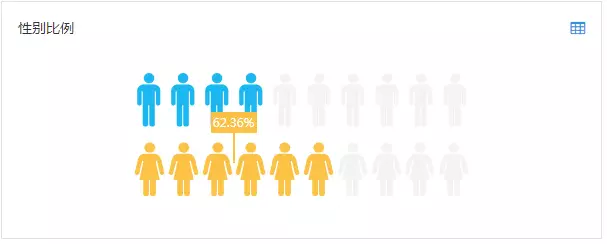
我们对渠道人群A进行画像分析,女性比例高达62.36%,其用户群对购物类App的兴趣也高于大盘用户,与我们高价值人群特征匹配度较高。
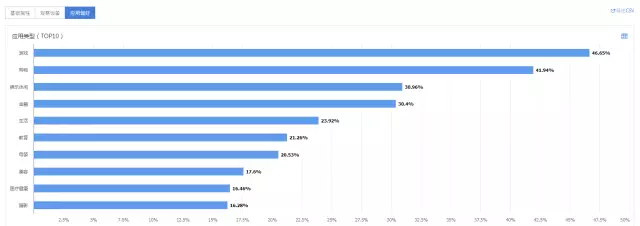
现在渠道A给我们带来的流量还比较小,但由于其渠道收益上ROI比例较高,且其群体画像与我们高价值用户的画像吻合度高,表现出了很高的投放潜力。
我们的改善方法是:调整渠道投放的比例,减少渠道B、渠道C的投放,增强渠道A的投放,以周为单位,迭代优化渠道投放效果,并监测ROI的变动。
4.渠道投放优化效果
在投放一周后,对新增用户有了增长,我们临时决议再次加大渠道A的投放比例。
这里是一个月的时间周期内,我们的新增用户数在渠道上的分布有了显著变化。

优化投放渠道前后,购买转化漏斗转化率的改变:
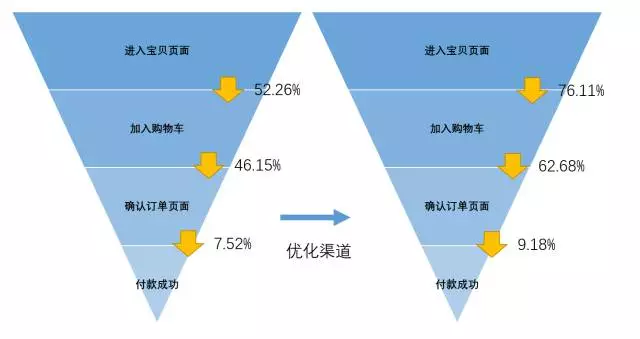
由于渠道A的平均客单价约是渠道D的1/2~1/3,我们的投入产出比例得到了优化。这主要依赖于通过数据分析找到了优质低价的渠道,降低了获客成本。
细分漏斗画像,改善关键节点
通过数据挖掘,我们发现了优质渠道A,其用户群与我们的高价值用户比较吻合,同时平均客单价约是原有主要渠道D的1/2~1/3,我们的投入产出比例得到了优化。
这主要依赖于通过数据分析找到了优质低价的渠道,降低了获客成本。
漏斗改进效果如下图:
那么,这个漏斗是否存在其他可以改进的地方呢?
当然有!我们的现实世界并非是简单的数据逻辑结构,很多结果都是多种原因综合导致的,我们可以用多种角度去分析同一个问题。
下面我们将结合漏斗分析与用户分群来做一个深度分析,通过漏斗的细致拆分和交叉对比,定位问题所在。
1.漏斗分析
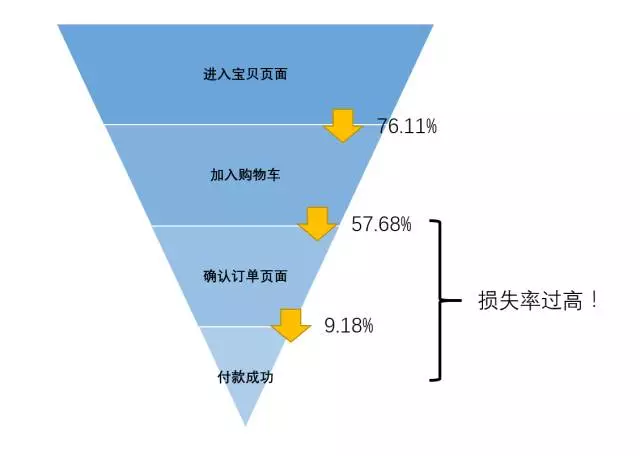
那我们就从这个漏斗开始分析:从上面都是漏斗中,我们可以看到,加入购物车之前的转化率都较高,但在购物付款的流程中,转化率急剧降低至14.65%,这里应该也有改进的空间。
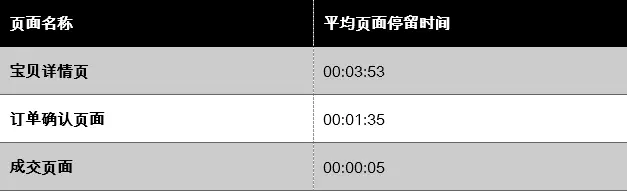
我们再看页面浏览数据,可以发现,用户在订单确认页面停留的时间长达95秒,这与我们平时的认知不相符。
2.漏斗拆分
为了验证我们的假设,我们建立两个小用户群——“确认要付款的人群”&“成功付款的人群”,即把漏斗中“订单人群”到“付款人群”进行了拆分,把确认付款的动作独立出来。
我们能够发现,在“确认要付款”到“成功付款”确实是损失转化的主要环节。
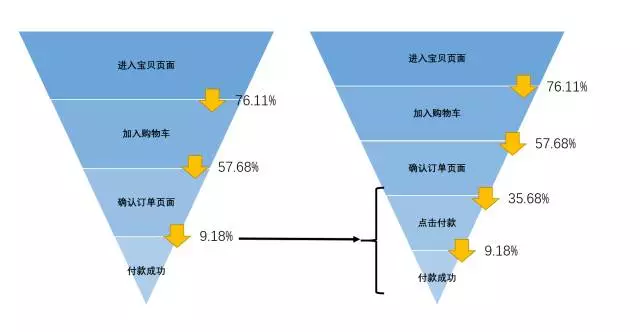
3.分群分析
我们看这群“确认付款”&“未成功付款”的人群:
我们姑且把这个人群叫做“付款失败”组。
在MTA中你可以通过设置用户分群设置来实现这一步的处理,如下图。
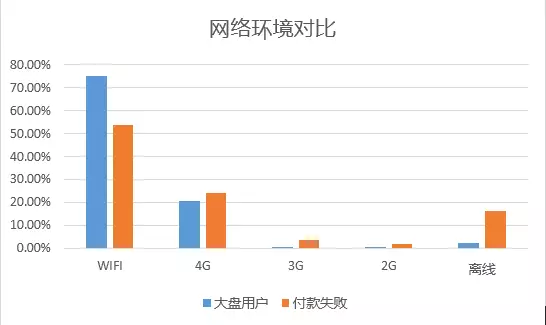
通过几个人群的对比,我们发现“付款失败”组的人群离线环境陡增约14%,另外,其3G、2G网络的比例要高于大盘人群(5.68% vs. 1.36%),且设备品牌中,相对机型较小众、低端。
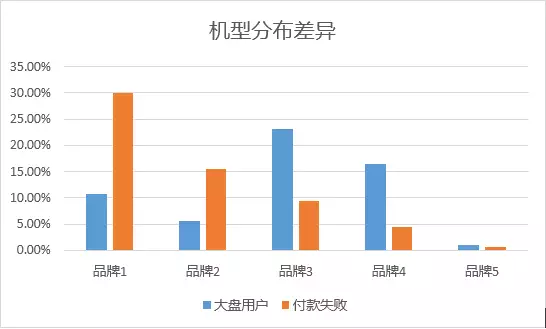
我们实际测试了品牌1和品牌2的实际几个机型,主要针对的就是付款页面的页面体验,存在以下问题:
机型适配性较差,开发时主要考虑的是现有主流机型适配,对小众机型的关注度较低;
页面卡顿严重,长达40秒以上的空白页面,严重消耗了用户耐心。
于是我们做了以下改善:
紧急修复版本,在小众机型的主要推广渠道上升级了版本适配性的App;
页面加载量优化,包括切割、压缩、删减图片,框架优化,预加载等策略,恶劣网络下加载速度提升至约15秒;
加载等待页面设计,增加了动画的等待页面,给用户卖个萌,增加用户等待的耐心。
4.效果验证
页面优化后,我们的漏斗转化流程有明显改善:
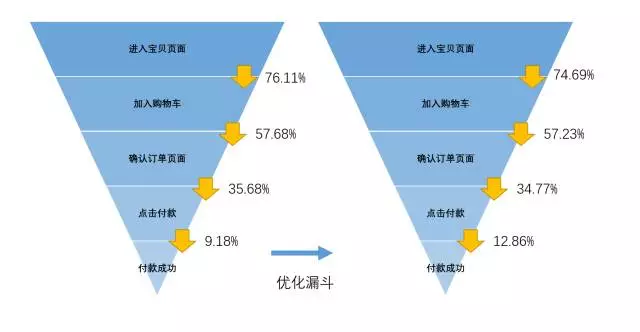
我们针对这群“付款失败”用户群所做的改善,为转化漏斗提高了3%的转化效率,这是非常大的一个收益。另外,我们在后续的漏斗改进中,还尝试结合了页面点击/页面流转的分析,删去了付款页面中不必要的信息、按钮,保证了付款流程的顺畅性,对于提升漏斗也有一定的作用。
5.总结一下
数据运营的优化思路其实就是通过细致拆分,把复杂的、多因子的事件分析拆分为独立的、单因子的归因分析,以确定改进的思路。
用数据说话,从埋点开始
数据只有采集了才能做分析,分析了才能实现价值。

图1.数据运营微笑模型
上图是数据运营解决问题的思路,但相对的,数据运营分析的需求,也驱动着数据埋点的优化。
有时候,我们可能会遇到这样的尴尬:
数到用时方恨少!
木有结论肿么破!
其实,数据埋点比我们想象得有更多挖掘的空间,有针对性的有条理的埋点能够帮助我们理清用户行为轨迹、抓住用户特征、解析关键路径。
但过多的埋点,可能会给App带来负担,也可能对App用户的流量、网速体验有影响,这都是我们需要考虑的因素。
全埋点、多采集,并不是数据分析体系构建的办法,反而是把分析挖掘的工作量后移,给数据分析带来很多负担。
较好的做法是:带着我们的分析目标与数据解读思路去埋点。腾讯移动分析MTA在数据埋点上做过多次优化,能确保多次采集一次上传的数据传输过程,减少对用户流量的影响,优化用户体验。
下面我们分几个层次来讨论埋点问题:
1.用户行为分析
通过埋点可以追踪用户的行为,即对App内的关键路径进行监测,这无疑是最常见也是最重要的应用场景。不同的App可能关注的埋点事件有很大不同。
例如,电商类App多关注的是订单成交;社区类App可能关注UGC内容的产生;阅读类App则需要关注内容的阅读。
用户埋点的场景很灵活,埋点可以统计的事件数据能和业务数据进行打通。
比如在新闻阅读的App中,将阅读新闻作为自定义事件,每一篇报道都带有不同的参数,可以得到阅读的大盘整合数据,也可以分析每篇报道的价值,甚至可以方便的实现阅读量排行榜等功能。
埋点是因业务场景需要而定的。
比如第二篇时讲到的漏斗细分中,有一个金融用户案例。在绑卡流程转化流失率过高的时候,需要定位每一个输入框的填写方式是否存在问题,这时埋点的密度会比一般情况要高很多。
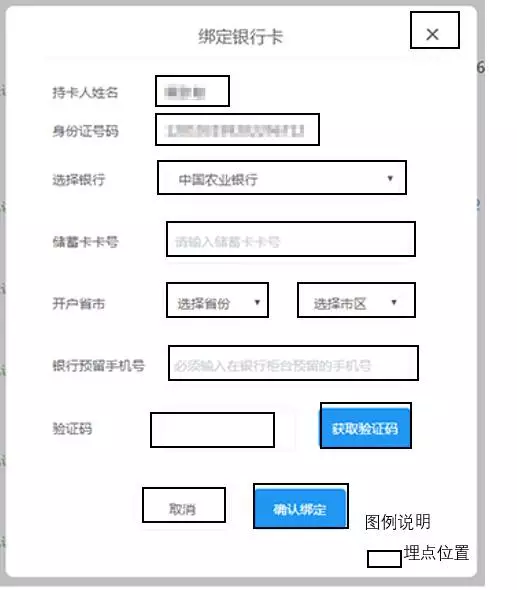
图2.定位问题时的埋点示意
上述埋点是基于我们想要定位“为什么绑卡页面转化率低”的需求。埋点之后,在绑卡流程漏斗中,MTA会生成一个详细填写页面的漏斗,从中我们或许能知道用户是在哪一步停止操作的,是否有改进的空间。
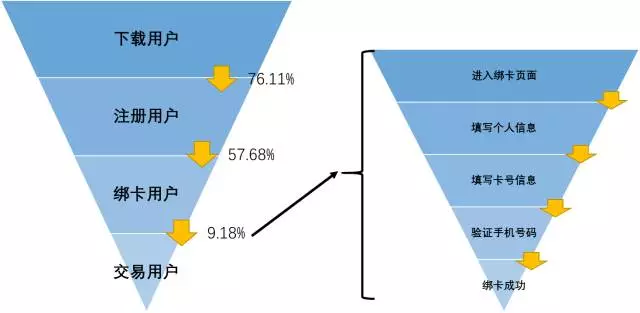
图3.漏斗拆解(由于业务数据敏感性,以上数据已做模糊处理)
但如果之后我们修复了问题,我们可能就不需要这么细致的埋点了,或者我们只需要对可能出问题的地方进行埋点监控。

图4.稳定后的埋点示意图
因此,业界所说的全埋点是一种未充分理解自身业务时采用的策略,很多时候也无法满足详细漏斗的追溯要求。而不必要的埋点带来了过量的数据上报,一方面加重了用户的流量负担,另一方面也不利于后期的复盘分析。
当然如果真的是业务上线了,点还没埋上,腾讯移动分析MTA新近推出了可视化埋点功能,可以由产品、运营同学通过web端配置埋点,云端下发至App中,随时调整App内的埋点策略,也是机智而有效的救急措施。
开发GG再也不用担心我漏埋点啦~~
2.用户人群分析
根据用户事件、来源渠道、同期群,甚至年龄、性别、地域等,我们可以把自己的App用户切割为很多小群体。
比如在订单购买的业务中,将订单金额作为参数上报,能够更好的分析用户的价值。
下图是一种消费用户分群的方式,以消费金额Monetary、消费频率Frequency和最近一次消费时间Recency,得到8个象限的用户,可以对不同的用户进行不同的运营推广策略。

图5. 消费用户分群模型
还是看这个电商App,当用于活动运营分析的时候,可能数据分析的视角和方式就不太一样了。
举个例子:618活动时间新注册(同期群)且完成过一次订单的这群用户,他们在活动期结束之后,会有哪些表现?
购买VIP会员的转化率高于平均活动水平→某个新的广告渠道带来了优质的新客户,该渠道可以继续投入,持续关注效果;
继续参与七夕节的活动→人群可能对活动信息比较敏感,适合推荐促销信息;
流失曲线&再次开启时间的关系是:2周内不再开启App的客户,87%都流失了→我们如果在新用户注册后1周左右的时间通过Push、短信、邮箱等手段唤醒用户,能够大幅提高留存。
通过把人群切分,去分析业务特性,能够加深对用户的理解,结合你的App触达手段,能够让你更好的与用户交流互动,实现业务运营的目标。
而这里的人群切分方式,就需要通过埋点定义出自定义事件,通过事件与其他条件的叠加、筛选,与不同事件、报表做交叉分析,就能够凸显核心用户群体的价值,精细化运营不同用户群体。
点击不同按钮、关注不同板块、甚至不同注册时间的人群都有不同的特性。
精细化的分析运营需要对业务的深入理解,需要学会切入分析的角度,解析你的用户的特征,了解你的用户,再由数据的需求去驱动埋点的配置。
3.解析核心路径
第三点是基于第二点的应用。通过切割用户人群,再回到业务关键路径上,去发现吸引用户、留住用户的奥秘。
举一个比较知名的例子:
在某知名社交App的数据分析运营分享中,通过不同的事件对比,可以发现10天内添加7个好友的留存率大大提高。
我们回溯一下,如果我们想要分析什么才是这个App留存率的关键,我们需要罗列很多的可能性,比如在平台上浏览100条新闻、引荐3名新用户加入、产生UGC内容或者是上传3张照片、玩过平台游戏。那么,我们需要对比这些人群,寻找在这些事件中哪些才是与留存率强相关的?
如果是添加好友的这件事,那么这个时间限是:注册时关注3人,还是一周内关注5人?
或者如果我们发现,引荐5名新用户,留存率非常高,但实际上,真的能引荐5名新用户的人群少之又少,那么这件事也不适宜我们去重点关注,因为给我们带来的成本太高了。

图6.自定义事件与留存相关度的分析实例
从这些关键事件中,我们要通过数据分析找到其中的核心路径,然后倾斜我们的资源去支持它。
4.总结一下
总的来说,埋点与数据统计,都是为业务服务的。关注哪些事件、为他们埋点是由于App自身的业务特性所决定。
埋点需要有的放矢,分析才能得到结论,迭代增长也将有迹可循。
似是而非的数据悖论
精细化运营能够帮助我们在数据的指导下进行产品路线、战略的调整,让产品改进的过程有章可循。
但有时候,我们也会遇到一些看起来有些诡异的数据陷阱。
1.案例数据
我们先看问题的描述:
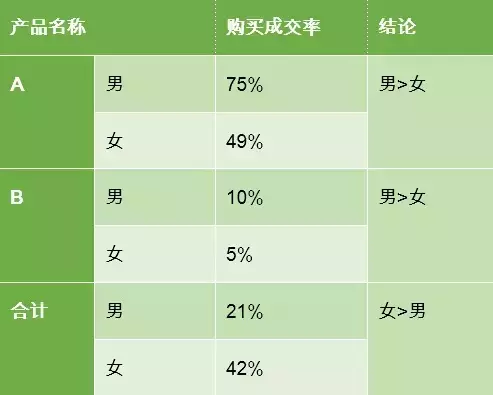
在产品A和产品B中,男性的购买成交率都是男性>女性,可在合计中,却是女性>男性。那么,这就有点懵了。
所以,到底应该拓展男性用户,还是女性用户呢?
可能我们的第一反应都是:是不是数据不准确啊?于是我们就有了这个案例……

2.原因定位
我们来追溯一下问题的来源
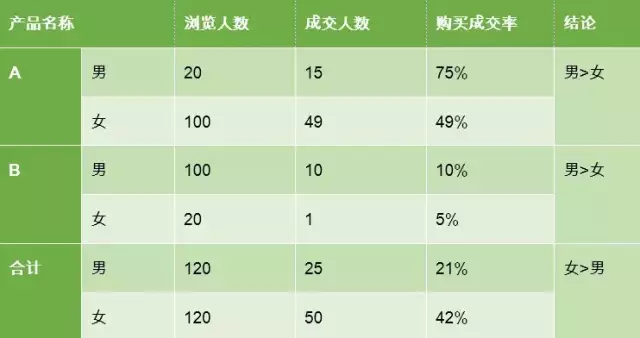
* 此处数据已做了模糊处理,非真实数据
从数据上我们可以看到,实际上,在产品A和产品B上,确实都是男性转化率高于女性,但由于产品B的转化率明显低于A,且男性群体大量被引导去了产品B,所以整体数据的转化率反而要低于A。
这在统计学上称为:辛普森悖论(Simpson’sParadox)
在分组比较中都占优势的一方,在总评中有時反而是失势的一方。该现象于20世纪初就有人讨论,但一直到1951年,E.H.辛普森在他发表的论文中阐述这一现象后,该现象才算正式被描述解释。后来就以他的名字命名此悖论,即辛普森悖论。
3.优化方案
回到这里的题目中,数据向我们展现了两个结论:
对于产品A和产品B,男性的购买成交率都大于女性;
产品B的平均成交率要明显低于产品A。
那么对于投放决策来说,我们还是偏好男性用户。在引流成本相同的条件下,男性的购买转化率较高。而针对产品A和产品B的分流推荐方式,可能还需要考虑两个产品的客单价与利润率。

从上图中可以看出,产品A属于低单价、低利润、成交率高的产品,产品B属于高单价、高利润、成交率低的产品。
那么如果在电商开拓期,希望引入更多用户,我们可能会侧重于推广产品A;如果平台已经有一定规模,希望能够提高人均利润率,降低百元成交量的获客成本,我们可能可以考虑多推广产品B。

(大概就是像这样的两个产品↑)
当然,这些的前提是在,引流成本相同的情况下。而往往实际问题的考虑中,我们还会需要考虑投放成本、投放效果、转化效果等问题,
4.案例总结
在数据运营的实战中,可能常常会遇到一些让我们觉得有点别扭的数据。
而在这些数据背后,其实蕴藏着很多的细节与能量。因此,建立详细的数据分析运营体系,理解用户群分离与归并的思路,让数据为你所用,这是很重要的。
回顾我们讲过的数据运营微笑模型~
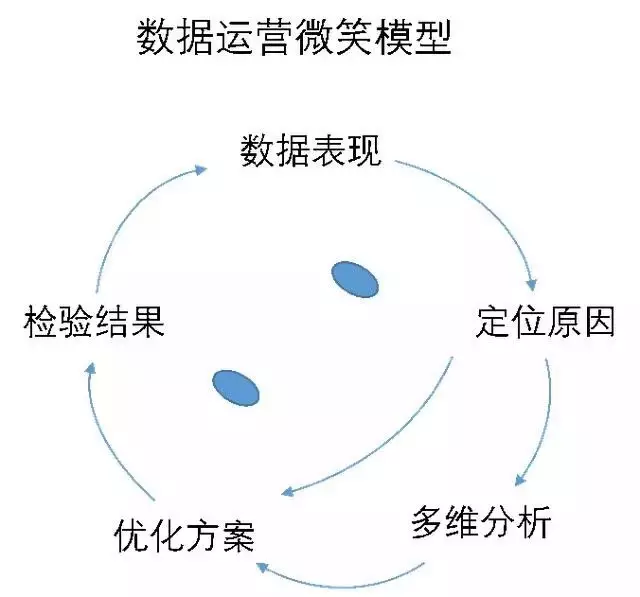
这一期我们讲的是在定位原因的过程中,对用户群拆分解析之后发现了其中的运营价值。
我们可以先通过自定义事件埋点,监测购买事件,同时上报购买商品的参数;然后通过用户分群设置筛选出购买事件中,购买参数等于产品A的人群,来得到我们想要的细分用户群体:
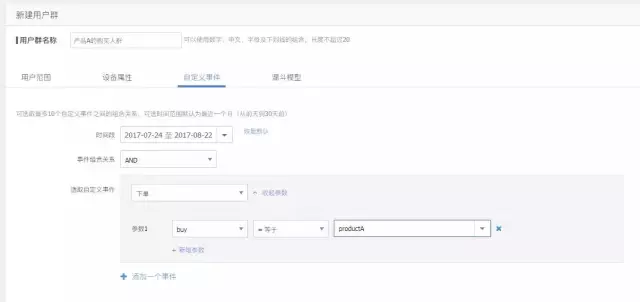
然后通过用户群体的计算与分析,得到该群体的人群特征,展开我们的数据分析工作。

 联系我们请点击:
联系我们请点击:



